
黒木玄 Gen Kuroki

- いいね数 389,756/311,170
- フォロー 995 フォロワー 14,556 ツイート 293,980
- 現在地 (^-^)/
- Web https://genkuroki.github.io/documents/
- 自己紹介 私については https://twilog.org/genkuroki と https://genkuroki.github.io と https://github.com/genkuroki と https://github.com/genkuroki/public を見て下さい。
2023年06月26日(月)

所得に対する比率とか考えてくれよー。消費税減らしたら貧乏人のほうがありがたいんだよ。そもそも消費税の逆進性すらわかってないで財政がどうのって、なんだよ。
sp.m.jiji.com/article/show/2...
タグ:
posted at 23:58:36


NHKの仮説検定の授業がひどい件、色々指摘したが全く修正されない。ウェブページの「優位」水準(正しくは「有意」)さえ修正されない。NHKからのメールにそのまま返信するのではダメなのか?電話で直接伝えたほうが良いのか?それとも、BPOに通報したほうが良いのか?
www2.nhk.or.jp/kokokoza/watch...
タグ:
posted at 23:56:13

こんなこと言ってますが、私は下っ端なので今のところ「オープンキャンパスの負担で研究が進まねぇ!」な事態にはなってないです。なんなら博士学生だった時の方が雑用に駆り出されてた。
ただ、このまま行くと近い将来、これらに従事することになり、それは私の望んだ未来か?みたいな気持ちでいます twitter.com/tunatuna_01/st...
タグ:
posted at 23:50:27

「誤差をともなってばらつくのはデータです」「仮説や真の値はばらつかないので確率的表現はできません」「「データが偶然のみでえられる」ことは統計モデルの仮定の一つ」 twitter.com/katzkagaya/sta... pic.twitter.com/GXvBBQhuVk
タグ:
posted at 23:39:08
#統計 U統計量の定義
U = Σ_{i=1}^m Σ_{j=1}^n h(Xᵢ, Yⱼ).
ここで、
h(x,y)= (x<yならば1, x=yならば1/2, x>yならば0).
Uは2群の標本XᵢとYⱼを数値の大小で勝負させ、mn通りのすべての組み合わせでY側の勝ち数。mnで割れば標本勝負での勝率になり、母集団勝負での勝率の推定量とみなされる。 twitter.com/genkuroki/stat...
タグ: 統計
posted at 23:31:22

Sato Shuntaro|佐藤俊太朗 @Shuntarooo3
プレプリントだけど、この論文はおもしろい。効果指標まわりをとても丁寧に整理している。
Risk ratio, odds ratio, risk difference... Which causal measure is easier to generalize?
arxiv.org/abs/2303.16008
タグ:
posted at 23:20:19

Hiromitsu Takagi @HiromitsuTakagi
このGoogleが「強調スニペット」で推奨する抜粋のサイト、見に行ってみるとこう↓書かれているのだが、ここまで見に来ないで(見に来たとしてもこの意味を読解しないで)、Googleの要約だけ見て間に受けるとドカン。
www.kdanmobile.com/ja/blog/busine... pic.twitter.com/F36MOQmUkG
タグ:
posted at 23:08:47
Hiromitsu Takagi @HiromitsuTakagi
実演してと取材が来たが「そんなの16年前にニュース7で流してるからそれ再放送しようよ」で済まそうとしたが、新しい話もした。「インターネットで検索すると、隠した情報を消去する必要がある点に触れていない方法が表示される」とあるのは、これ↓が原因かも?という話。
www3.nhk.or.jp/news/html/2023... pic.twitter.com/kaODEj0KPZ
タグ:
posted at 23:03:48
Sato Shuntaro|佐藤俊太朗 @Shuntarooo3
・リスク比は効果の大きさだけでなく、ベースラインの有病率によって値が変動する。
・リスク比はアウトカムの有病率が増えるとnullにバイアスされる
・オッズ比は純粋に効果の大きさを示す
タグ:
posted at 23:03:44
Sato Shuntaro|佐藤俊太朗 @Shuntarooo3
オッズ比よりもリスク比・差が好ましいとよく言われるけど、オッズ比がリスク比より良いよ!という論文。
The Odds Ratio is “portable” across baseline risk but not the Relative Risk: Time to do away with the log link in binomial regression
www.sciencedirect.com/science/articl...
タグ:
posted at 23:03:43

#統計 勝率による優劣の付け方だと、3群以上でジャンケン状態が生じることもあることにも注意。
Mann-WhitneyのU検定よりも頑健なBrunner-Munzel検定を使ってもこういうことが起こることに注意が必要になります。
無条件で便利に使える検定法はないです。
理解度に応じて誤用のリスクが減るだけ。 twitter.com/genkuroki/stat...
タグ: 統計
posted at 23:03:04
実質金利が低下してだけで、YCC修正の可能性が高まるという議論はミスリード。また直近では、イールドカーブ自体の形状がなめらかなので、歪みを理由にした修正の可能性も低いと思う。実質金利をなんちゃって推理すると、10年物国債金利を利用した予想実質金利=0.39-1.143(BEI)=-0.753(おそらく… twitter.com/i/web/status/1... pic.twitter.com/F3RkKmpmHf
タグ:
posted at 23:00:22
#統計 以上の説明を読めば、Welchのt検定は
母平均の差に関する検定
で、Brunner-Munzel検定(Mann-WhitneyのU検定の上位互換とみなせる)は
勝率と1/2の差に関する検定
なので、やっていることが全然違っていて、互換性がないことも分かる。違いを測定するための指標は目的に合わせて選ぶべき。 twitter.com/genkuroki/stat...
タグ: 統計
posted at 22:56:52

ごまふあざらし(GomahuAzaras @MathSorcerer
みんな利便性を求めてPythonを書きます。
実行速度が気になってきます
N年後にJuliaへの移植案件が増えます。
飼い主が喜びます。
と思うじゃん?世の中はそんなに甘くない(´・ω・`)
N年後にその分野に飼い主いるとは限らないので
タグ:
posted at 22:56:35
@kyHibisyoujin @nekonyannyan821 大学入試は大学教員が採点するのでそのような理不尽な減点の危険性は極めて低いです。模試で減点されたら、その模試が模擬試験の機能である「入試を模擬すること」に失敗しているだけのことです。減点されて不利益はありませんので、堂々と減点されてください。
タグ:
posted at 22:56:33

@seijimatsuyama 鳥取県で「有害図書」指定されたら、全国でネット販売の取扱が中止になった例もありますしね。
www.yomiuri.co.jp/local/kansai/n...
タグ:
posted at 22:51:34

#統計 2群の標本サイズがm,nのときMann-WhitneyのU検定で使うU統計量に関する
p̂ = U/(mn)
は
2群から無作為に1人ずつ選んで数値が大きい方が勝つというルールでの片側の勝率の自然な推定量
になっています。p̂が1/2から離れ過ぎていたら、Mann-WhitneyのU検定では有意差があることになります。 twitter.com/genkuroki/stat...
タグ: 統計
posted at 22:40:22

#酷誤 #十分 教科書に合わせて改訳することは絵本にあった造本上の制約から自由になる可能性でもあるというご指摘twitter.com/LingkoNIKI/sta...。勉強になります。
posted at 22:35:20
(問題文で聞かれてないのに)「最大値をとるときのxを書かないと減点」も「場合分けは相反にしないと減点」もおかしいけど、それらですらないスーパー謎採点。 twitter.com/nekonyannyan82...
タグ:
posted at 22:27:59

ジェンダーギャップ指数の元資料について「買わないと読めない」というコメントがあったが、こちらで読めます twitter.com/akinori_ito/st...
タグ:
posted at 21:51:31


コーエン・N・チューリング「ケインジアン vs マネタリストの区別はもはや時代遅れである」(2023年5月23日) (経済学101) econ101.jp/distinction-be...
タグ:
posted at 21:25:34

“経済マスコミで頻出する文面「この10年間は極めて緩和的な金融政策が取られた」…新古典派の見解では、中央銀行の金融政策はインフレ期待の安定を目的としているため、こうした文面は意味不明である” / “コーエン・N・チューリング「ケインジアン vs マネタリストの区別は…” htn.to/3xSeyY34KQ
タグ:
posted at 21:07:21

現状の経済論争は、低金利・公的債務拡大政策でほぼ全員一致している「新古典派経済学」と、マスコミやIMFを代表とする利上げ・財政黒字を提唱する「新オーストリア学派」にあるとする、「ケインジアン vs マネタリストの区別はもはや時代遅れである」をお届けします。
econ101.jp/distinction-be...
タグ:
posted at 20:50:14


お前らが数学どころかマトモに算数すらできないのは「感覚的に自然/違和感がある」なんて「感覚で」問題に対峙してるからやで。
と誰かが教えてやらなければならないw
??「地球が引っ張ってる?そんなわけないやろ!!!」
タグ:
posted at 18:36:59

高校の採点(軸が定義域の真ん中にあるときを書かずは-2点)で生徒が落ち込んでた。なあ唐津東、お前は絶対に許されないことをしたぞ?首洗って待ってろ pic.twitter.com/AQ3Hv2M6GH
タグ:
posted at 18:24:31

「3枚の皿に🍓を2個ずつ」「2個ずつの🍓が乗った皿が3枚」を「2個/皿×3皿」と教えたからといって「3皿×2個/皿」が間違いになるわけではないし、「児童には「2個/皿×3皿」が自然な理解で、それしか理解できない」わけでもない。なんなら「逆順」の方が多いという報告もあるtwitter.com/genkuroki/stat...
タグ:
posted at 18:05:24

とうとう入院待機ステーション稼働。対応が遅かった関西の第4波を受け第5波前に数多く設置。第8波で再開した都道府県数多。ここまで行くのは「通常医療が提供できない状態」を間接的に反映しており「もうすぐ医療崩壊」でなくて沖縄は既に逼迫しているのですね。Hold tight
www3.nhk.or.jp/news/html/2023...
タグ:
posted at 17:56:19

OokuboTact 大久保中二病中年 @OokuboTact
@kankichi57301 @sekibunnteisuu > それは九九もその順だからです。
半九九じゃないんだから、逆順も九九に含まれているから、交換法則も簡単にわかる。
タグ:
posted at 16:20:31



どうかみなさま、お助けください。
2年前のニュース映像ですが、こちらもどうかご覧ください。
www.youtube.com/watch?v=ez5pLf...
タグ:
posted at 15:19:46
→公立学校と違い、私設の外国人学校であるコレジオ・サンタナには、行政からの公的支援は一切ありません。サンタナの先生たちもみな、十分な給料をもらうことなく、手弁当で勤めています。今回のクラファン、いちおう当初の目標は達成しましたが、まだまだ支援が必要な状況です。→
タグ:
posted at 15:17:37
→コレジオサンタナには、病気や障害をもつ子どもも多く通っています。工場で働く親たちも経済的に苦しく、毎日残業をせざるをえません。そのあいだサンタナが子どもたちを預かっています。ここで3食のご飯を食べる子どももたくさんいます。→
タグ:
posted at 15:16:06

【ご寄付のお願い】みなさまにお願いがあります。滋賀県のブラジル人学校コレジオ・サンタナが、ふたたび経営難に陥っています。物価高や雇用保険料引き上げ、保育施設での安全装置の義務化や有資格者配置などで、非常に苦しい財政状況に陥っています。→
congrant.com/project/nposan...
タグ:
posted at 15:13:54


@kt_serious @Iutach 3×10をみて、3本足のタコ10匹の意味だと思う子がいたら、
その子に教えるべきことは、少なくともかけ算の順序じゃないですよね。
タグ:
posted at 14:37:55
#統計 次の問題は面白いです。
問題:二項分布モデルでのP値函数
pvalue(x|θ=θ₀)
=min(1, 2cdf(Binomial(n,θ₀),x), 2(1-cdf(Binomial(n,θ₀),x-1))
から、Clopper-Pearsonの信頼区間 qiita.com/tabintone/item... が得られることを確認せよ。
タグ: 統計
posted at 14:33:17
かけ算順序擁護論者は、「順序批判派はこうなんだ」というピント外れな妄想を恥ずかしてもなく開示するから、見ていて面白いよね twitter.com/turbo0421/stat...
タグ:
posted at 14:24:27
#統計 1つ上の練習問題の答えが
ja.wikipedia.org/wiki/%E3%82%A6...
にあります。
二次不等式については高校で習います。
Wilsonの信頼区間はWaldの信頼区間よりも性質がずっと良いです。
そういう良い性質を持つ信頼区間を得るために高校数学の二次不等式がもろに役に立つということです。
タグ: 統計
posted at 14:23:11
話題になってる一人の委員のYCCをめぐる発言は以下。植田総裁ぽいけど、どうなんでしょうかね。あとイールドカーブをめぐって「主な意見」が白熱?したのは昨年末から三月の会合までで、四月は沈静化し、六月もそう盛り上がってるようには思えない。YCC修正いまは必要ないとしてるのは安達委員ぽい twitter.com/Bank_of_Japan_... pic.twitter.com/A7vqAKzGtQ
タグ:
posted at 14:18:52
#統計 以下の問題は基本的!
問題:データの数値xと統計モデルMのパラメータθの値に関する仮説θ=θ₀についてのP値
pvalue(x|θ=θ₀)
の計算の仕方が分かっている場合に、パラメータθに関する100(1-α)%信頼区間
ci(x|α)={θ₀|pvalue(x|θ=θ₀)≥α}
をもっと具体的に表せないかについて考えてみよ。 twitter.com/genkuroki/stat...
タグ: 統計
posted at 14:08:09

3×10という式を見て真剣に「この子は3本足の🦑が10匹いる、と考えてるのかもしれない!」と言う奴がいたら、其奴の正気に強い疑問を抱いて当然だと思います。 twitter.com/kt_serious/sta...
タグ:
posted at 14:03:37

実際に買う買わないは置いといて
このエアハブについて100万近いアクティビティが付くとはビックリ。
少なくともタイヤの空気について、これだけ多くの人の関心ごとだったと言うのが分かってホッとする。
もっと無関心かと思ってたんだよ。 pic.twitter.com/UIOUuDDyp5
タグ:
posted at 13:48:35
逆に、もし係数が整数に限るなら「整数と同様」「できるかぎり分解」等の記述から4も2×2に因数分解しないといけないように読めますが、実際の教科書や指導書の解答はそうなっていませんし。
タグ:
posted at 13:30:17

尾身先生の献身に頭が下がる思い。
ほかの医者なら「私は好きにした。君らも好きにしろ」と放り投げてもいいくらいの状況になってしまっていると思う。
尾身氏「第9波始まった可能性」 コロナ巡り首相と意見交換:中日新聞Web www.chunichi.co.jp/article/716912
タグ:
posted at 13:13:15
この「9a² - 1/16 b²」など、いよいよ「係数は先にくくりだす」の意味が不明になって、「どっちでもいい」としない限り、中学数学の「因数分解」の独自理論が自己破綻している。 twitter.com/esumii/status/...
タグ:
posted at 12:59:50
流行状況が悪い状態が続いています。メタコビでは時間を振返っての報告をしていただけます。発病直後につらい時は回復後に入力下さい。以下でアクセスいただければと思います。モニタリングのためにご協力をお願いします。
covid-data.jp
タグ:
posted at 12:31:01
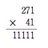
数研出版「これからの数学 3」
p. 31 問4 (6)
x² - 1/9
問5 (9)
x² + x + 1/4
p. 249 6 (6)
9a² - 1/16 b²
他複数
タグ:
posted at 12:29:37

#超算数 を追ってる身からすると異常性がわかるが、そうでないとちょっと気づきにくいだろうか? twitter.com/Mgk_Shonaidori...
タグ: 超算数
posted at 12:22:01
① x² + 2/3 x + 1/9 = (x + 1/3)²
② (2) y² - 1/36 = (y + 1/6)(y - 1/6)
③ 1/4 + x + x² = (1/2 + x)²
タグ:
posted at 12:20:43

@Mgk_Shonaidori @kuri_kurita 掛け算の順番にしてもそうですけどもう理屈じゃないんですよ、算数じゃなくて『算数道』です。
「師匠の言い付けを理屈抜きに守り、教えを拝受しなくてはならない」というやつ。指導側のプライドが満たされ、被指導側はいい子ちゃんになれる。もはや数学的本質とは何の関係もない
タグ:
posted at 11:53:57
「中学数学の範囲では因数分解のパートで係数が有理数というのは出てこない」はファクトとして誤りです。例:大日本図書「数学の世界 3」(検定済教科書)p. 30-32「プラス・ワン」①②③の問題と解答
タグ:
posted at 11:46:36

「ふしだら警察」は基本的には自由の敵だと思うんだよ。エロいことはそれだけではなんら悪くなかろう。
君が「気持ち悪い」と感じるからといって、それを理由に規制させようとするのは誤り。個人の好き嫌いは規制の理由にはならない
タグ:
posted at 11:05:22

「Aの予算を削ってBに回せ」は財政均衡主義で、要するに緊縮派の言い分になってしまうので、やめるべきです。
「Bの予算が足りないなら、予算を増やせ」が正解。Aとはなんの関係もない。
財源は国債発行で賄えます。それでなんの問題もない。
国債を財源に消費税を減税するべきですよ
タグ:
posted at 09:50:29
#統計 Rのfisher.testでのP値と信頼区間の不整合は、exact2x2::exact2x2を使えば解決する。 twitter.com/genkuroki/stat...
タグ: 統計
posted at 08:45:23

#統計 おそらく、区間推定と仮説検定を説明している章が完全に分かれていて、それらの表裏一体性について何も説明されていない教科書で勉強した人たちが、統計ソフト開発の中核を担って来たのだと思われる。
だから、互いに不整合なP値と信頼区間を同時に表示するソフトの側が多数派になった。 twitter.com/genkuroki/stat...
タグ: 統計
posted at 08:43:41
#統計 データの数値xと統計モデルMのパラメータθの値に関する仮説θ=θ₀のP値pvalue(x|θ=θ₀)が与えられているとき、信頼区間はci(x|α)={θ₀|pvalue(x|θ=θ₀)≥α}で定義できます。このとき
θ₀∈ci(x|α) ⇔ pvalue(x|θ=θ₀)≥α.
JMPに限らず、この原則を守っていない統計ソフトが多い。Rもそう。 twitter.com/shuntarooo3/st...
タグ: 統計
posted at 08:42:00
スイミーや山椒魚を「男の物語」とくくってジェンダーポリティクス的に批判したツイート(削除済み)に対する反応。
twitter.com/LazyWorkz/stat...
まあこの是非はともかく、教科書にもっと女子の物語を入れるべきだとは思います。
なんなら家なき子レミのようにスイミーをTSさせてはどうか。 pic.twitter.com/YlCeBohEzn
タグ:
posted at 08:41:16

原作では「同調意識」だの「異なる属性をもつ個人への排斥性」だのみたいな事は、まったく匂わされてもいないのだが。 pic.twitter.com/fNgo9e9D1F
タグ:
posted at 07:39:54
この指摘はとても興味深い。
そして『「でも」がなければ話の意味が変わってしまう(から教科書向けの改変はおかしい)』という意味のことを言っている人もいるけど、そこに「でも」を期待してしまうのは何故なのか。 twitter.com/b8oqzxadrm8yjx...
タグ:
posted at 07:30:34

物理系はJulia利用する例が増えてきて、システム系はRust、フロントエンドはReact/TypeScriptを使うのが最近は多い印象だな。まずは用途別にメジャーな言語学んでおくと良さそう。
タグ:
posted at 06:15:10

#ChatGPT vs #Bard for #julialang pic.twitter.com/DrmJ6ox7C5
posted at 05:51:42
「Aと教えられたらAと答えないと×、Bと言う答えが正しいかどうかなんて関係ない」と教えてるから、Bで〇だと混乱する。 twitter.com/kale_aojiru/st...
タグ:
posted at 02:52:08

Every Little Thingsの「スイミー」(『結婚できない男』主題歌)が、「まだスイミー」(「まだ結婚できない男」主題歌)で書き換えられてる! おのれ文部省め!
……しかしなんでこれスイミーなんだろ。元ネタの共産主義的なとことか微塵も残ってないなあ。 pic.twitter.com/foYlZNKcfg
タグ:
posted at 01:45:44
『スイミー』の訳文が絵本版と教科書版で少し違うという件で細かく喧々諤々してるなか、アクアリストは我が道をゆく大きな指摘をしていて、ちょっとおもしろいです。 twitter.com/ALIENHARUCHAN/...
タグ:
posted at 01:27:00
ごまふあざらし(GomahuAzaras @MathSorcerer
人工データ生成スクリプト。お試しあれ。
github.com/AtelierArith/V...
#Julia言語
タグ: Julia言語
posted at 00:21:42
ごまふあざらし(GomahuAzaras @MathSorcerer
github.com/AtelierArith/R...
これの多言語版つくりたいな。
#Julia言語
タグ: Julia言語
posted at 00:15:05
#酷誤 #十分 「スイミー」の改変は訳者の谷川俊太郎自身によるものでしたtwitter.com/Shyboy_of_/sta...。スレッドでは個別の改変が取り上げられ、指導要領のどの要請を満たすためなのか議論されています。
posted at 00:13:33
