
黒木玄 Gen Kuroki

- いいね数 389,756/311,170
- フォロー 995 フォロワー 14,556 ツイート 293,980
- 現在地 (^-^)/
- Web https://genkuroki.github.io/documents/
- 自己紹介 私については https://twilog.org/genkuroki と https://genkuroki.github.io と https://github.com/genkuroki と https://github.com/genkuroki/public を見て下さい。
2018年02月28日(水)

どうやら最近 Github が TLS のバージョンを変えたので、 Win7 で UpdateしてないようなPC ではGit ベースのパッケージのインストールができないみたい。
MS Easy Fix も効かんかった。プロキシ環境下なんで OS のせいではないのかも…?
タグ:
posted at 23:56:57

 非公開
非公開
タグ:
posted at xx:xx:xx
非公開
タグ:
posted at xx:xx:xx
非公開
タグ:
posted at xx:xx:xx
と、言うわけで Julia を Jupyter で動かそうとしたけど、この issue に当たってうまく動かんかった。
ーーー
github.com/JuliaLang/juli...
タグ:
posted at 23:44:09
非公開
タグ:
posted at xx:xx:xx


ポエムですらないぜ… #はてなブログ
(Julia) Julia使ってみた記念。 - niszetの日記
niszet.hatenablog.com/entry/2018/02/...
タグ: はてなブログ
posted at 23:05:58
NowBrowsing: Julia 0.6-dev の新しい Type System に触れてみた。 - Qiita: qiita.com/antimon2/items...
タグ:
posted at 22:45:58

@p3_55 【30本足の鶴2羽という考えを示してるわけではないと思いますが‥‥】
そういう事でしたら、
「3×2 と書いたら『3本耳のウサギが2羽いる』という意味になってしまう」と教えることは、間違いですよね?
参考→ www.asahi.com/edu/student/te... #掛算
タグ: 掛算
posted at 22:37:16

さくつば『トータルウィン』鬼の漢字 @TsubasaTeacher
いろいろ調べてみたが、英語圏の場合、「問題文の順序が逆」ってこと。だから、日本のように「(一つ分)×(いくつ分)」ではなく、「(いくつ分)×(一つ分)」でやっているってことですね。
タグ:
posted at 22:31:10

須山敦志 Suyama Atsushi @sammy_suyama
確率モデリングを導入すれば強化学習のような「予測+意思決定」が当てはまるような実問題はもっと多くなってくるはず.少なくとも僕は今まで,「あ,これ本当は強化学習の問題だけど部分的に予測だけ取り出してるだけだ」って思ったことが何度かあります.
タグ:
posted at 22:24:11
須山敦志 Suyama Atsushi @sammy_suyama
多くの場合,強化学習は「実環境をモデリングする」という観点が抜け落ちていることが多く,そのせいで解空間が膨大になり,ゲームみたいに徹底的な反復的な探索ができるようなタスク以外は成功していないのだと思います.要は,ツールやアルゴリズムを当てはめるだけでは実問題は解けないということ.
タグ:
posted at 22:21:25
須山敦志 Suyama Atsushi @sammy_suyama
とは言うものの,僕自身,強化学習を使って(ゲームとかじゃない)実問題に取り組んだのは一度きりで,それ以来ずっとやりたくてうずうずしているのですが,まったく機会が回ってこないですね. twitter.com/sammy_suyama/s...
タグ:
posted at 22:17:43
非公開
タグ:
posted at xx:xx:xx
須山敦志 Suyama Atsushi @sammy_suyama
それほど知られていないですが,ベイズが真の実力を発揮するのは能動学習や強化学習などの意思決定までも含むような枠組みです.「ベイズは過学習しない」はただの宣伝用文句であり,単純な数値を当てに行くタスクから抜け出した先に大きなご利益があります.
タグ:
posted at 22:13:39



さくつば『トータルウィン』鬼の漢字 @TsubasaTeacher
算数の掛け算順序問題だけど、
今のところ、
「(一つ分)×(いくつ分)」にしなくてはいけないということはなんとなくわかった。でもなぜ、その順序なの?
「(いくつ分)×(一つ分)」ではだめなの?
確か海外では、「(いくつ分)×(一つ分)」だと思ったんだけど。
#掛算
タグ: 掛算
posted at 22:08:47

@tonotonos いきなりで失礼します。
【割合でも使える】と言われるので、これをお聞きしたいと思います。
「食塩水の中の、食塩の量」を求めるとき
(食塩水全体)×(濃度) と
(濃度)×(食塩水全体) の
どちらが正しいのでしょうか? #掛算
タグ: 掛算
posted at 21:55:26
非公開
タグ:
posted at xx:xx:xx
@p3_55 【考え方を 順序で表すのはなんで間違いなんですか?】
私の持っている本に、添付のような事が書いてあります。
ここで、30×2=60 という式は
「30本脚のツルが2羽いる」
という考えを表しているのかどうか、という事です。#掛算 pic.twitter.com/THVIsxM3cI
タグ: 掛算
posted at 21:36:31
非公開
タグ:
posted at xx:xx:xx

オンラインでの小規模なR, Python, Juliaの環境共有にはbinder: 既存サービスとの比較 on @Qiita qiita.com/uri/items/2dd7...
タグ:
posted at 21:04:33

富谷(助教);監修 シン仮面ライダー @TomiyaAkio
@hottaqu @hashimotostring お返事おくれてすみません(橋本さん、回答ありがとうございます)。
論文でも触れているのですが、対象にした物質の相転移が一次にちかいと言うことでCFTとの相性は悪い可能性があります。
それと今回の仕事では、フレームワークを提示したので色々な応用・拡張があると思っています。
タグ:
posted at 20:47:22
非公開
タグ:
posted at xx:xx:xx
非公開
タグ:
posted at xx:xx:xx
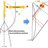
@hashimotostring @TomiyaAkio 磁場と磁化の実験データのカーブを、フーリエ展開やテーラー展開と同様に14個くらいの適当な少数のパラメタで再現できることが本質のように思えるので、その程度の自由度を持ったパラメタであれば、同じ1つの実験データから重力場h(η)もA(η)もDLで作れる可能性があるかもしれません。推測ですが。
タグ:
posted at 20:08:33
@hashimotostring @TomiyaAkio 地平面の境界条件を課す曲がった時空の場の方程式の代わりに、適当な、しかし割と一般的な境界条件を課した平坦時空の複素スカラー場の運動方程式で、同じ磁場と磁化の実験データからDLで仮想的な電磁ポテンシャルA(η)も同様に決められるようにも思えます。
タグ:
posted at 20:04:37
20年前の東工大のクラスター計算機が1Gフロップスで、今の東工大のGPUスパコンが10ペタフロップスだから、1000万倍。今1日で終わる計算は20年前には三万年かかる計算なわけで、そりゃ人工知能などで質的に違うものができるようになるわけだ
タグ:
posted at 20:04:31

日本の労働法は前時代的な労働の在り方を前提としていて,時代に即していないなどという向きの方には,真っ先に賃金の時効期間延長に賛同して頂きたいもんである。賃金の短期消滅時効ってのは19世紀のフランス法そのまんまなんだぞ。
タグ:
posted at 20:03:42

@gilbert_yumu そうです。これが統計学における最尤法の標準的な定義です。たとえば
y=a+bx+ε、ε~Normal(0,σ)
というモデルでは、
w = (a,b,σ), p(y|x,w) = (1/√(2πσ²))exp( -(y - (a + bx))^2/(2σ²) )
です。一応念のため。
タグ:
posted at 20:02:46
非公開
タグ:
posted at xx:xx:xx
@gilbert_yumu 私が説明した統計学における最尤法の標準的な定義は理解できましたか?不十分なら説明を付け足します。
最尤法の定義を共有せずに話を先に進めても意味がないと思います。
タグ:
posted at 19:58:10
@hashimotostring @TomiyaAkio ありがとうございます。やっぱり初期値次第で準安定点にひっかかってる可能性もありそうですね。機械学習の宿命的部分かも。なお磁場と磁化の実験データのグラフは、その曲線自体が割と単調でありさえすれば、揺らぎが小さい(相転移点からはずれた)場合でも、滑らかなh(η)が出てくる気がします。
タグ:
posted at 19:57:08
@gilbert_yumu 最小二乗法だけなら単なる線形代数ですが、
y = β_0 + β_1 x + … + β_{M-1} x^{M-1} + ε, ε~Normal(0.σ)
というモデルでβ_iたちとσを最尤推定した結果のβ_i達の値は最小二乗法で求めたβ_i達と同じです。εの部分を正規分布でフィッティングすることと最小二乗法は等価になります。
タグ:
posted at 19:55:30
裁量労働拡大は,それが必要だと思ってる経団連よりの政党から堂々と出しゃいいだろと思うが,立法趣旨が明らかに逆方向を向いてる労働時間上限規制と一括法案で出すって手口は,やり方自体卑劣過ぎるだろと思う
タグ:
posted at 19:54:30

一件だけ屋根の雪が不自然に溶けてる家を警察が家宅捜査したら屋根裏が大麻工場で家主逮捕
@アムステルダム(ライセンス無しの大規模栽培は違法) pic.twitter.com/oNu0dFpYLg
タグ:
posted at 19:48:20
非公開
タグ:
posted at xx:xx:xx

橋本幸士 Koji Hashimoto @hashimotostring
@hottaqu @TomiyaAkio 統計は取っていません。ランダムに選ばれる初期条件に大きく依存しますが、速い時で数十エポックくらいでしょうか。遅い時は1000エポックでも到達しません。
タグ:
posted at 19:39:22
オンラインでの小規模なR, Python, Juliaの環境共有にはbinder: 既存サービスとの比較 on @Qiita qiita.com/uri/items/2dd7...
タグ:
posted at 19:38:19

ぎるばーと / T. Shimizu @gilbert_yumu
@genkuroki ありがとうございます!パラメータの区別なく尤度最大化で同時に決めるのですね。
タグ:
posted at 19:37:27
@gilbert_yumu 通常の統計学における最尤法の定義はこうです。
1. 確率モデルp(y|x,w)を与える。
2. サンプル(X_1,Y_1),...,(X_n,Y_n)を得る。
3. 尤度函数L(w)=p(Y_1|X_1,w)…p(Y_n|X_n,w)を最大にするw=w^*を求める。
4. p(y|x,w^*)を予測分布とする。
y=a+bx+ε、ε~Normal(0,σ)ではw=(a,b,σ)になります。
タグ:
posted at 19:28:52
@gilbert_yumu 最小二乗法は本質的に正規分布モデルの最尤法なので常に正規分布の分散を最尤推定していることになります。
予測分布の定義が不明なら説明します。
ここでは、確率モデル&サンプル→予測分布というシンプルな話をしています。
わざとオーバーフィッティングさせる話をしています。
タグ:
posted at 19:24:51
#統計 添付画像はN=30の最尤推定のケース
大きなMでオーバーフィッティングしまくっています。
再度強調:更新前からAICとBICのプロットが含まれていました。 pic.twitter.com/qVJPhalKLs
タグ: 統計
posted at 19:01:32
#統計
gist.github.com/genkuroki/ca0e...
を更新しました。
サンプルサイズN=10,20,30の20と30を追加し、最尤法の方の予測分布のプロットを±σを±2σに変えました。更新する前からAICとBICのプロットも含まれていました。
添付画像はN=30のベイズ推定のケース pic.twitter.com/680QmzweFh
タグ: 統計
posted at 18:59:29

明松 真司(Shinji Akemats @minami106
ちなみに、Javaでは「メソッドのオーバーライド」というややこしい名前の別概念があるので注意が必要…笑 #java
タグ: java
posted at 18:53:43
明松 真司(Shinji Akemats @minami106
メソッドのオーバーロードは「メソッドのシグネチャ(引数の並び)が異なっていれば、同名メソッドを複数宣言できる」仕組みのこと。名前が同じでもどうせ実際に呼び出したときの引数の並びを見ればどれを呼び出せばいいか分かる。という面白い仕組みです。こんなに名前が違うとは。 #Julia言語
タグ: Julia言語
posted at 18:52:31
明松 真司(Shinji Akemats @minami106
多言語の勉強がやはり役に立っているなと感じるタイミングが多いです。たとえば、メソッドの宣言における「多重ディスパッチ」というのは、これだけ突然読むと難しくて何がなんだかですが、Javaでいうところの「メソッドのオーバーロード」のことだと気づけば一撃で理解できます。#Julia言語
タグ: Julia言語
posted at 18:50:08
明松 真司(Shinji Akemats @minami106
Julia言語の勉強を毎日ちょっとずつやっていますが、Juliabook(yomichi.hateblo.jp/entry/2016/08/...)を使って勉強してます。わかりやすくて神です。 #Julia言語
タグ: Julia言語
posted at 18:48:11
非公開
タグ:
posted at xx:xx:xx
非公開
タグ:
posted at xx:xx:xx


とりあえず本田圭佑公式アプリの運営者に「彼のユダヤ陰謀論発言を諌めて欲しい、このままでは取り返しのつかない結果になる」とメールを送った。
twitter.com/yoox5135/statu...
タグ:
posted at 17:00:39
本田圭佑の公式アプリを入れて中を覗いてみた。やっぱユダヤ陰謀論に罹患してるっぽい。アプリはSNSみたいになってて彼本人といろんな人がやりとりしてるんだけど「陰謀論はあかん」と諌める書き込みは見かけられない。下手するとこのアプリが陰謀論のスプレッダーになりかねんぞ。 pic.twitter.com/yrOFsJt0wp
タグ:
posted at 16:52:18
昔から、将棋や囲碁が強い子供は算数や数学も強い傾向がある。どちらも、悪しき「パターン学習」や「丸暗記」で対応できない点が共通している。「その場で考える能力」がないと楽しめない点も共通している。
タグ:
posted at 16:48:36
将棋とかで、覚えた定跡手順をひとつでも外れた途端に何をやったらよいか考えられなくなるようだと、そもそも将棋という楽しいゲームを遊んでいることにならないと思う。
他のあらゆることも同じ。
悪しき「パターン学習」や「丸暗記」は完全に廃棄しないとダメ。
タグ:
posted at 16:43:05
覚えたパターンから外れても何とかできるような理解の仕方をしていれば、悪しき「パターン学習」や「丸暗記」ではない。
悪しき「パターン学習」や「丸暗記」は就学前からやるべきではない。
悪い癖がつくと数学的な事柄の理解はあっというまにダメになる。
タグ:
posted at 16:40:00

@keroppih0710 @TsubasaTeacher 「学校教育への不信感が拡がるのはよろしくない」と学校関係者が認識したのなら、「だから不信感を拡げるな」じゃなくて「不信感が拡がらないような教え方をしていこう」とすべき。
タグ:
posted at 15:41:42
@keroppih0710 @TsubasaTeacher 不信感を拡げるのは良くない、という人もいますが、信用してはならないものを信用する方が有害。信用してはならないものに対して不信感を拡げるのはいいこと。
タグ:
posted at 15:40:35
@keroppih0710 @TsubasaTeacher だから、「バツになっても気にしないように。今の学校での算数教育は信用してはいけませんよ」と、学校教育への不信感を拡げる必要があります。
タグ:
posted at 15:39:43
@keroppih0710 @TsubasaTeacher バツにするのは教師の側が「今度は正しい答案を書いて欲しい」というメッセージである。通常ならそうして正しい答案を書くための努力することで理解につながるのだが、#超算数 だと、逆に理解が遠ざかる。
タグ: 超算数
posted at 15:38:45
@keroppih0710 @TsubasaTeacher しかし、おかしな教え方の害を軽減することは出来ると思っています。
それは、「今の小学校での算数教育はおかしなことになっている。だから、テストで答えが合っているのにバツになっている、という事があっても、子どもはちゃんと理解しているのだからバツは気にしないで」と広く訴えること。
タグ:
posted at 15:37:05
@keroppih0710 @TsubasaTeacher また、学校教育関係者全般が、情報を外に出して公の元で議論することを嫌がっているようなので、
学校教育を変えると言うことでの解決はかなり難しいと思っています。
タグ:
posted at 15:35:27
@keroppih0710 @TsubasaTeacher 愚かな教師が我流で愚かな教え方をしている例はあるのですが、それとは別に中枢部がおかしなイデオロギーに染まっているので、教員が研修など受ければ受けるだけ、おかしな算数教育をすることになります。
タグ:
posted at 15:34:12
@keroppih0710 @TsubasaTeacher この問題は根が深くて、日本数学教育学会や筑波附属小学校算数部や大学の教育学部の先生や教科書会社などの、算数教育の中枢を占める人がおかしな考え方に染まっているというのがあります。
教育行政のあり方一般の議論としては、予算の増額などの要求はすべきだと思いますが、
それとはまた別問題
タグ:
posted at 15:32:35

田崎統計とポプテピ単行本の大きさが同じ位だから、帯を合わせたら思いのほかそれらしくなった(?)。田崎さんがポプテピを統計力学で評論してるみたい。 pic.twitter.com/qKS5fRTLRF
タグ:
posted at 15:31:09

@sekibunnteisuu @TsubasaTeacher 続)先ずは教職員の増員を図る為に教育関係費予算の倍増が必要です。お金があれば解決する訳ではありませんが、必要なお金が確保できない現状が続けば状況は悪化の一途です。教員の個人技に任せた現状を見直しチームで業務を遂行するよう是正しなければ、この国教育は何時までも中世から抜け出せない。
タグ:
posted at 15:25:46
@sekibunnteisuu @TsubasaTeacher 御意、納得できる[科学的な]理由などありません。
全員がそうではありませんが大きな要因の一つは初等教育の教員育成失敗による教員の能力不足、一部能力不足教員による児童・生徒へのマウンティングという恥ずべき行為の発露です。しかし教員のみを責めてもこの問題は解決しません、(続
タグ:
posted at 15:19:30

うがあ.これは速い.
JuliaでCVのシミュレーション書いてみたけど,十進BASICで書いたのをそのまま移植するとBASICの1.5倍くらい「遅い」のが,単純に計算ルーチンをfunctionにまとめただけで,BASICの20倍くらい「速く」なったw
実質的には,全体をfunction~endで括っただけなのだがw
タグ:
posted at 13:40:12
#超算数
『わり算には2種類ある!』
⇒ ameblo.jp/minmin-tomato/... #アメブロ @ameba_officialさんから
posted at 12:40:33
#統計 続きは以下のリンク先
twitter.com/genkuroki/stat...
「予測分布について理解していない人は何も理解していない」と言っても過言じゃないかもしれない、という感覚が段々強くなって来ました。
「パラメータの推定」という中途半端な発想は誤解の原因になりやすいことは確実だと思う。
タグ: 統計
posted at 12:29:57
#統計
訂正:「予測分布を考えればオーバーフィッティングの問題が緩和される」という主張は誤り。最尤法だと全然緩和されない。
反省:「全否定という方針だと会話し難い」というバイアスのせいでおかしなことを書いてしまいました。ごめんなさい。
twitter.com/genkuroki/stat...
タグ: 統計
posted at 12:25:25
非公開
タグ:
posted at xx:xx:xx

今朝の読売の記事。奥さんからやべぇってメール来たけどガチでヤバい。
Q 若い教員が残業しない。働き方改革もあり指導できない
A 遠慮せず指導してよい。若い教師に「教師は天職」と感じてもらうために必要な指導だ。ブラックと思われようが手抜きは許されない。 pic.twitter.com/JaInfWuok2
タグ:
posted at 12:17:46
掛け算の順序教育を擁護する hishakaijin.com/2017/12/07/pos...
大したことは書いていない。通常の掛け算順序指導擁護論同様のくだらない主張。
#掛算
タグ: 掛算
posted at 12:17:12
非公開
タグ:
posted at xx:xx:xx

怖いなぁ。この瞬間にこの学校で何人ものこどもがいわれのない暴力を受けてる事が分かるわけだ。そして多分教委も文科省も放置するのやろか。「イジメ」も問題やけど此方は更に「虐め」込みの酷い話。どう考えても道理がおかしい。 #掛算 twitter.com/fmty/status/96...
タグ: 掛算
posted at 11:59:51
@naomi091123 物理の公式、アルファベット順にしないとならないとしたらかなり面倒くさい。
高さh、質量mの位置エネルギー mgh じゃなくて ghm とか
タグ:
posted at 10:58:39
@naomi091123 アルファベット順も、そうすることで同類項が見つけやすいという面もあるが、常に強要する必要はない。
しかし、中学数学程度だと、大して手間にならないから強要しがち。
高校で扱うような複雑な式で逐一アルファベット順だの有理化だのやってられない。
タグ:
posted at 10:56:22
@naomi091123 中学数学でも、分母の有理化だの文字式の積はアルファベット順だのと言うくだらないローカルルールがあります。分母の有理化が必要な場面はあるし、分母を有理化は出来ないとまずいけど、「常に分母は有理化していないとならない」などと指導する教師が居る。
タグ:
posted at 10:54:10
@naomi091123 狭い世界しか見ていないのだと思います。複雑な式になったら、書き順だの、分数の横棒を定規で、なんてやってられないわけだけど、そういうのが見えていない。自分が教えていることが将来どういうことに発展していくのかが分かっていないから、その場でしか通用しないくだらないことを教え込む。
タグ:
posted at 10:22:42
twitter.com/genkuroki/stat...
中高生を教えていて思うのは、分数の書き順なんかどうでもいいから分かりやすく書いてくれ、ということ。
分子や分母に分数が来たときに、横棒の長さが一緒だったり
=2/3という場合、横棒が=と同じ高さでなかったりがある。
タグ:
posted at 10:07:52

新しい顔を編集しながら絵柄を完成さしてますけど、ここ最近気づいた事ですが、アニメスタイル3Dは顔の右左を違う形で作ると3Dぽさおそろしく減ります、お勧め☆ pic.twitter.com/BFDV7cruBz
タグ:
posted at 09:36:28

一部の教員しかやらないし時間外の作業だから通常業務とはいえない。それで手当もなく,経費も自腹だったら,良問を作る意欲も出ないしミスも増えるだろう。これも突き詰めれば法人化の悪弊。
京大・阪大入試ミス:問題作成、教員の重荷 自腹で教科書、手当なし - 毎日新聞 mainichi.jp/articles/20180...
タグ:
posted at 09:28:52
非公開
タグ:
posted at xx:xx:xx
非公開
タグ:
posted at xx:xx:xx
非公開
タグ:
posted at xx:xx:xx
非公開
タグ:
posted at xx:xx:xx
非公開
タグ:
posted at xx:xx:xx
非公開
タグ:
posted at xx:xx:xx
非公開
タグ:
posted at xx:xx:xx
@35941229 いきなりで失礼します。
【掛け算の順番ではなくて】とのことですが、
これは #掛算 の順番です。
このような言い分によって、バツにされます。
参考→ www.asahi.com/edu/student/te...
なお、私は「順序どうでも良い」論者です。
タグ: 掛算
posted at 08:58:57

オンラインでのR, Python, Juliaでの小規模な環境共有にはbinder: 既存サービスとの比較 on @Qiita qiita.com/uri/items/2dd7...
タグ:
posted at 08:57:57
非公開
タグ:
posted at xx:xx:xx

「教科書通り」に教えると #超算数 を発現するし、「独自の工夫」を模索するとTOSSに帰依するし、教職課程は一体何を教えているのか… twitter.com/sekibunnteisuu...
タグ: 超算数
posted at 08:52:19


遅刻したら「罰金300円です」→なぜか遅刻数が2倍に増えてしまう
遅刻の件数(託児所のお迎え)
A. 遅れても罰ナシ:週8件
B. 遅れたら罰金300円:週16件〜
罰金という「遅刻への対価」が、お金を払えば遅刻が許される「遅刻チケット」のように機能してしまった😰
ヤル気の科学 より pic.twitter.com/xZfcD1vGvx
タグ:
posted at 08:17:54
非公開
タグ:
posted at xx:xx:xx
非公開
タグ:
posted at xx:xx:xx
非公開
タグ:
posted at xx:xx:xx
twitter.com/aogiri_m2d/sta...
#Julia言語
function f(x::AbstractArray{T,1}) where T<:Real
sum(x)
end
なら大丈夫。x::Array{T,1}と書くと部分配列を渡せなくなってはまります。よくわからなかったら、引数の型宣言を一切しない方が安全。適切に書いておけば、速度面での劣化はない。
タグ: Julia言語
posted at 03:29:19
数学が得意で正直もののベイズちゃんが「おまえは重過ぎる」と言われてプチっと切れて、崩壊型ギブスサンプリングで高速回転しまくるとか。(崩壊型ギブスサンプリングについては須山さんの本を参照)
タグ:
posted at 03:00:38

以上を見れば、私が
* ベイズ推定法さんは正直である
と何度も言っている理由がわかると思います。
最尤法さんは推定の失敗を隠してオーバーフィッティングした予測分布を教えてくれる場合があります。
マンガ化、イラスト化に結構向いているネタだと思う。
タグ:
posted at 02:52:00
#Julia言語 ソースコード
gist.github.com/genkuroki/ca0e...
最尤法の部分は私が書いたのですが、それを除けば
github.com/sammy-suyama/B...
のコピペです。
タグ: Julia言語
posted at 02:43:37
#統計 #Julia言語 1つ目の添付画像は須山さんの
github.com/sammy-suyama/B...
で作ったベイズ推定法による予測分布。Mは多項式の次数-1です。2つ目は私が作った最尤法(最小二乗法)による予測分布です。ベイズ推定の予測分布と違って、最尤法の方はM=10でオーバーフィッティングしまくっています。 pic.twitter.com/wAVI4bk5bc
posted at 02:41:59

非公開
タグ:
posted at xx:xx:xx
非公開
タグ:
posted at xx:xx:xx
非公開
タグ:
posted at xx:xx:xx
@TsubasaTeacher ■餅の問題は、2年生に教えた事によれば 55×8×6 の筈です。
しかし、「8台の臼を用意して、各々で1回に55個つくり、それを6回くりかえす」と、頭に浮かんだ順に式を書けば、8×55×6 となってしまいますね。
まさに「問題文に現れた順」です。#掛算
タグ: 掛算
posted at 01:01:53
@TsubasaTeacher ■鶴亀算では「まず30匹ぜんぶ鶴と仮定してみよう。するとそれぞれが2本ずる脚があるから 30×2 だね。」と言ってしまうので、2年生に叩き込んだ事に対して違反となります。
■「10分間の2倍を求めるときは、10×2」の筈ですが、なぜか「学年×10分」と口を滑らせてしまいますね。
続きます #掛算
タグ: 掛算
posted at 00:58:40
@TsubasaTeacher 他に
「1.5g を mg に換算するというとき、1.5×1000 か 1000×1.5 か、決まらない」
というのもあります。
happylilac.net/keisan-tanni6n...
2年生時点で叩き込んだ事に従えば 1000×1.5 の筈ですが、ついつい「右にゼロみっつ付ける。だから ×1000 とすればイメージしやすい」と言ってしまうのでしょう。
#掛算
タグ: 掛算
posted at 00:55:12
@TsubasaTeacher 【こだわる人に納得させられる解答】とのことなので、案をお示しします。
もっとも、こういう物を見せられても、納得したくない人は納得しませんが。
www.pref.chiba.lg.jp/kyouiku/shidou...
e-school.e-tokushima.or.jp/awa/es/donari/...
#掛算 pic.twitter.com/kGSVT7luk4
タグ: 掛算
posted at 00:51:09

これがこれまでに学んでいた統計的学習理論のフレームワークと違うと感じたところだった。知っている限りでは仮説(入力に関する出力の関数)を点推定し、bias-variance分解の文脈から高varianceな現象を過剰適合というと認識していたが、そもそも論点が違った...。 twitter.com/genkuroki/stat...
タグ:
posted at 00:44:33

それでは、まず、「ハッピーになれる算数」という本が教材としてまともなのか検討してみるべきではないでしょうか。「文章題を式にホンヤクする」とか書いてある本が教材としてまともなのか、意味を理解できないAIとやらとどこが違うのか? #掛算 #超算数 twitter.com/noricoco/statu...
posted at 00:44:04
@genkuroki もしそうでないのなら、これまでの過剰適合の定義に対してもパラメータ推定の標準誤差を考えるべきだと思いますし、そこがしっくりきませんでした。
タグ:
posted at 00:39:44
非公開
タグ:
posted at xx:xx:xx
@genkuroki あー、なるほどです...。確かに...。bias-variance分解によって過剰適合が定義されるという認識だったので、その意味で予測分布がベイズ推定の目標であることはそうであっても点推定を考えるべきという認識でした。
タグ:
posted at 00:38:44
さくつば『トータルウィン』鬼の漢字 @TsubasaTeacher
「算数の掛け算の順序」
順序をこだわる理由を子供にも保護者にもうまく伝わる方法を教えてください。
ちなみにぼくは、「どっちでもよい」と思っている人です。
欧米では日本と逆らしいし。
むしろ、こだわる人に納得させられる解答があると嬉しいです。
調べてもよくわからん。
ゆるーく募集中。
タグ:
posted at 00:38:29
私みたいな弱小オブ弱小なアカウントにわざわざ別垢作って絡んでくる人が現れるなんてさすがtwitter(もう消えたみたいだけど)。すごいわー。さすがにちょっとぎょっとしたけど、そうかこれが、これこそがSNSの華ってやつなのね。
タグ:
posted at 00:36:26
@genkuroki 統計的学習理論の枠組みでは仮説集合の中から適切な仮説(入力に関する出力の関数)を一つ選んでくるという認識をしています。その選ばれる仮説に対してvarianceが高い場合それを過剰適合と呼ぶという認識をしています。それが間違っておりますでしょうか。
タグ:
posted at 00:33:19
@genkuroki ご教示いただいてありがとうございます。意味が理解できたと思います。予測分布については、そうだと思うのですが、疑問に思うところはその点ではないような気がしております。
タグ:
posted at 00:32:25

「3×4」の生徒(8人)と [式が正答&絵も正しい] 生徒(8人)
「4×3」の生徒(21人)と [式が誤答&絵も正しい] 生徒(21人)
これは同じ生徒な気がする。
個人的には絵が描けていれば理解したとみなして良いと思う。 twitter.com/genkuroki/stat...
タグ:
posted at 00:32:21
非公開
タグ:
posted at xx:xx:xx

Juliaでは、文字列連結は * なんですが。+は左辺と右辺が可換である演算に使うのが普通で、*は可換とは限らないので*を使う、みたいなことが書いてありました。 docs.julialang.org/en/stable/manu...
タグ:
posted at 00:08:57
須山敦志 Suyama Atsushi @sammy_suyama
一般的な変分推論の最大の問題点は事後分布があるパラメトリックな分布に限定されているところで,これは明らかにMCMCに比べて劣っている点です.じゃあノンパラメトリックにすれば良いという話になるのですが,今のところそれに一番近そうなのは
arxiv.org/abs/1511.06499
タグ:
posted at 00:04:41
