
黒木玄 Gen Kuroki

- いいね数 389,756/311,170
- フォロー 995 フォロワー 14,556 ツイート 293,980
- 現在地 (^-^)/
- Web https://genkuroki.github.io/documents/
- 自己紹介 私については https://twilog.org/genkuroki と https://genkuroki.github.io と https://github.com/genkuroki と https://github.com/genkuroki/public を見て下さい。
2019年01月21日(月)

仙台の青葉山から八木山にかけて、古くから戦後しばらくの間まで亜炭を掘っていて、それを燃料によく使ったようだ。オレはわからないのだけれど、亜炭は燃やすと煙がぎょうさん出て、なんとなく甘いにおいがするらしい。それが古い仙台っ子の郷愁を感じるにおいなんだそうで。
タグ:
posted at 01:14:32
おかげで、今でもちょっと掘るとすぐに亜炭層や坑道にぶち当たる。震災のあと、地下鉄東西線を掘って、今の環境科学研究科棟あたりを大規模開発してたけれど、ずいぶん亜炭が転がっていた。埋木細工ができそうなのもあった。
タグ:
posted at 01:19:56

Jupyter Notebookを貼っただけの記事が割と伸びてる。Qiitaもnbviewer
みたいにJupyter Notebookのファイルを投げるだけで投稿できたらいいのに
Jupyter Notebook上でSymPyの数式とLaTeXコマンドを組み合わせて表示
qiita.com/ceptree/items/...
タグ:
posted at 01:25:35
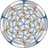
This is the same tiling/rotation/projection as the last. Only the initial orientation has changed, by 𝜋/4. It is easier to see here that the animated rotation is about an edge.
Also, hoping to improve quality, I'm experimenting by posting as a looping video instead of a gif. pic.twitter.com/3XHSLRxm5G
タグ:
posted at 04:55:09

ツイッターではこういった理科や数学の基礎知識のない初等教育教員の話題に事欠かない。教育学部の卒研や修論には格好のテーマだと思うけど、いかがですか?
例えば、「小学校教員における理系学力低下の現状と実害、およびその対策」なんてタイトルで… twitter.com/SciCafeShizuok...
タグ:
posted at 06:09:47

クックパッドのレシピで「酵素」が出てくるものの月ごと頻度を、「味噌汁」の場合と比較してみた図。後者はクックパッドの成長とともに増えてきているが酵素は2011年ごろから急増。大震災が「自然指向」に影響したのかと思っています。 pic.twitter.com/U1I3KShlQG
タグ:
posted at 09:41:47
なお、クックパッドにレシピに登場する「酵素」という言葉は、「生きた酵素を体に」みたいな使い方で、ほぼ100%の人が酵素とは何か理解していないようです。理解していたら「酵素メニュー」なんか出てこないよね。
タグ:
posted at 09:56:54
同意!教育学部の学生さん、私のアカウントにある娘の答案は論文材料にご自由にお使いください〜 #超算数 #超国語 twitter.com/scicafeshizuok...
posted at 10:25:46

tdual(ティーデュアル)@Matri @tdualdir
文系でプログラマーになったけど色々失敗して3年半で会社を辞めた話|denkigai|note(ノート) note.mu/denkigai/n/naf...
タグ:
posted at 11:20:46
tdual(ティーデュアル)@Matri @tdualdir
この人の当時の気持ちはもちろん完全に理解できないし、少し意図と外れてるからもしれないけど、「努力してプログラミングしている」人たちはそりゃ才能ある人達には及ばないけど、才能ないと自覚したからといってプログラミングをやめないで欲しい。それは社会には必要であることは間違いないから。
タグ:
posted at 11:22:21
tdual(ティーデュアル)@Matri @tdualdir
これだけのIT社会になったんだから好きな人達だけで社会全体のプログラミング案件を回せるわけない。「努力してプログラミングしている」人たちも居ないと回らない。そして別に才能ある人に及ぶ必要なくね?って思う。その人に適した環境はあるんだから。
タグ:
posted at 11:24:16
プロフィールに「特別支援教育」とある方からこういう反応がきて、びっくりしている。不器用な子供は算数の内容を理解しても「もちろん×」で「アホ」なのか。心底から驚いている。 pic.twitter.com/GQSJvvxMQV
タグ:
posted at 12:30:55

@SciCafeShizuoka この方のツイートを少しさかのぼって見てみましたが、どうも、「私はもちろん×にしますよ」という意味ではなくて、「そういう子ももちろん×にされてしまう。そんな評価をする教師はアホだ」と言いたかったのではないかと思われます。(それにしてもあまりにも言葉足らず…)
タグ:
posted at 12:39:20

#統計 訂正
誤「MAP法とベイズ推定法の近藤」
正「MAP法とベイズ推定法の混同」
LASSO正則化などはMAP法の特別な場合なのですが、それをベイズ推定(推測)と混同するようじゃ、用語の体系がめちゃくちゃになる。
twitter.com/genkuroki/stat...
タグ: 統計
posted at 12:51:52

Ninja DAO | CryptoNi @CryptoNlnjaNFT
40歳過ぎて握力が強くなる日本の女性たちである。 pic.twitter.com/ZxYu4og1Ly
タグ:
posted at 12:59:10
Ninja DAO | CryptoNi @CryptoNlnjaNFT
This was not at our school. twitter.com/marxindo/statu...
タグ:
posted at 13:00:14
@nonchan_pdx このリプライには私も驚いて、この方のツイートを少し遡ってみたんですが、真面目な方のようなので不思議に思っていました。クリティカルな問題なんだから、もう少し丁寧に書いてくれても良いのに… ^^;
×にするアホな教師がいると現場でも思っているということで、ツイートはこのままにします.
タグ:
posted at 13:05:15
囲碁ガチ勢が国民的アニメの“囲碁シーン”を一年間録画して検証→とある結論に至るが、さらにそこにプロ棋士が参戦し新たなる真実が浮かび上がる様子 - Togetter togetter.com/li/1310990 @togetter_jpより
タグ:
posted at 13:19:34
大学教授たちがひぃひぃ言いながら真面目にセンター試験の監督をしている一方で、受験生からはこんなふうに見られている。死にたくなるので、もう辞めさせて欲しい。 pic.twitter.com/JwyrKLieF1
タグ:
posted at 13:26:49

 非公開
非公開
タグ:
posted at xx:xx:xx

@SciCafeShizuoka 今はtwitterがあるので、こうした大学側からの視点も現役の高校生は知る事が出来る訳で、もうちょっと合理的な運営になる事を微かに期待。ある高校の先生は「試験監督は大学入試センターの人がやっている」と信じていたし。大学入試センターどんだけ人員がいるんか。
タグ:
posted at 13:39:23
非公開
タグ:
posted at xx:xx:xx
@holozoa55 センター試験は約50万人が受験します。1つの試験室で50人が受験するとして1万室。一部屋に2人の監督者が配されますから2万人。これは監督者だけで、サポート役の事務職員も含めれば5割増し、合計3万人くらいは動員されていますね。これが2日間… 外注すれば新たな雇用が生まれる!
タグ:
posted at 14:20:29

@tabunmori まず、「信用区間」と「信頼区間」で意味が全く違うことを認識してから質問し直して欲しいと思いました。
「数学的モデルAの中で95%の確率で~が成立する」と言われただけでは実用にならないので、数学的モデルA,B,C,…をデータに基いて評価し、適切な意味でベストなものを選ぶ必要があります。
タグ:
posted at 14:55:00
@tabunmori 統計学における「データに基いて数学的モデルを評価することの重要性」は赤池弘次さんが強調していたことです。
日本語による解説が結構沢山あってインターネット上で読めるものもあります。
「統計のハウトゥー本」を読むのをやめて、偉大な先達に学ぶべきだと思います。
twitter.com/genkuroki/stat...
タグ:
posted at 15:03:57
@tabunmori そのスレッドで私は「数学的モデルをデータに基いて評価する方法」ですでによく知られているものについて説明しています。
twitter.com/genkuroki/stat...
タグ:
posted at 15:05:49
@tabunmori ちなみに、p値も数学的なモデル内部での確率に過ぎません。
p値の定義は「帰無仮説の数学的モデル化になっていると考えられる確率分布において、サンプル以上の偏りが生じる確率」です。帰無仮説の数学的モデル化と「◯◯以上の偏り」の設定を確定させればサンプルからp値が確定する。
タグ:
posted at 15:10:06
@tabunmori t分布を使った区間推定の意味での「95%信頼区間」の95%も、p値の場合とほぼ同じいみで、数学的モデル内部での確率です。
(1) 数学的モデルとして正規分布モデル p(y|μ,σ)=e^{-(y-μ)²/(2σ²)}/√(2πσ²) を考える。
(2) 現実世界から得たサンプルY_1,…,Y_nは数学的モデルに従っていると仮定する。続く
タグ:
posted at 15:38:26
@tabunmori (3) Mをサンプルの平均、U²をサンプルの不偏分散とし、T=(M-μ)/√(U²/n) とおくと、上の仮定より、Tは自由度n-1のt分布に従う。
(4) Iは自由度n-1のt分布において確率が95%になる区間[-m,m]であるとする。
(5) 現実世界から得たサンプルから、T∈Iとなるμ全体の集合の区間を計算できる。
タグ:
posted at 15:44:27
@tabunmori (6) そのようにして得られたμの区間を95%の信頼区間と呼ぶ。
95%は正規分布モデル内部で構成されたt分布する確率変数Tに関する確率です。それ以上の意味はありません。
タグ:
posted at 15:46:34
@tabunmori p値も、95%信頼区間の意味での95%も、数学的モデル内部での確率に過ぎず(信頼区間の場合は色々で分かりにくい)、決して現実世界での確率ではありません。
しかし、p値は帰無仮説の数学的モデル化をデータ(=現実世界で得たサンプル)に基いて評価するための指標として役に立ちます。
タグ:
posted at 15:52:11
@tabunmori μが95%の信頼区間に入っていることは、サンプルY_1,…,Y_nが平均μ,分散σ²(分散は何でも良い)の正規分布のサンプルになっているという仮定のもとで(ここで数学的なモデル内部に入っている)、Tが自由度n-1のt分布での確率95%区間に入っていることを意味しています。続く
タグ:
posted at 15:59:54
@tabunmori この意味で、μが95%信頼区間に入っているか否かを見ることは、平均μの正規分布モデル達(分散は任意)をデータY_1,…,Y_nに基いて評価していることになります。
μが95%信頼区間に入ってなければ、平均μの正規分布モデル達(分散は任意)はデータ的にはあまり信用できないと判断される。
タグ:
posted at 16:03:05
@tabunmori 以上のように、よく使われている統計学の道具はほぼ常に「数学的モデルの評価をデータに基いて行うこと」をやっているとみなせます。
回答が非常に長くなってしまいました。
私は統計学のど素人に過ぎないことに注意し、自分で議論を再構成できた部分以外は信用しないようお願いします。
タグ:
posted at 16:05:37

@tabunmori 統計学ど素人でない人が、p値、95%信頼区間の意味での95%が数学的モデル内部での確率に過ぎないことを強調し、ベイズ統計の95%信用区間の意味での95%も数学的モデル内部での確率に過ぎないことを強調し、統計学はお墨付きを与えるための道具ではないことを強調してくれるようになるとよいと思います。
タグ:
posted at 16:11:38
@tabunmori お墨付きを与えることは不可能であっても、数学的な仮定のもとで、数学的なモデル達をデータに基いて評価する方法が用意されていることもクリアに説明して欲しいと思います。
お墨付きにならない理由は、モデル達の評価を確率的に失敗する可能性を統計学の文脈では排除できないから。
タグ:
posted at 16:14:30
いつまでもJuliaを書かない人
「日本語の資料が…Pythonが…パッケージの充実度が…」
Juliaを書く人
「学校の課題はJuliaで書いた。」
「Juliaで〇〇をプロットしました。」
Juliaに慣れすぎた人
「無意識にパッケージ化して公開してた。」
「Jeffが東京来るって連絡が来た。」
タグ:
posted at 16:35:46
(1) 真の確率分布を計算するためにベイズの定理(という名の条件付き確率の定義から自明に出て来る大したことがない結果)を使う場合(例:モンティ・ホール問題)
と
(2) 未知の確率分布をそのサンプルから推定するときにベイズ統計を使う場合(これは非自明)
を明瞭に区別していない解説は問題あり。
タグ:
posted at 16:45:26
そういう区別で杜撰な上に、「主観確率でベイズ統計を正当化しようとする行為」が重なっている解説は屑そのもの。
「頻度論vs.ベイズ主義」という暗黒の歴史に関する解説で、主観確率に基くベイズ統計の正当化をきちんとクズ扱いしていない(ゆえに解説側がクズである)ものが結構出回っている。
タグ:
posted at 16:45:28
具体的には
www.amazon.co.jp/product-review...
異端の統計学 ベイズ
シャロン・バーチュ マグレイン
のレビュー
を見ると、私は読んでいないが、読者を「頻度論vs.主観確率」のような暗黒の歴史解説で惑わせるよろしくない本であるように私には見えた。
タグ:
posted at 16:45:29
p値と95%信頼区間に関するよくある解説の問題点は「どのような数学的なモデルをデータに基いて評価しているのか」という視点を強調していないことだと思う。
数学的モデルをデータに基いて評価することは科学の基本中の基本なのに基本に忠実な解説になっていない。
タグ:
posted at 16:53:23
その害は、2×2の分割表での独立性検定(めちゃくちゃよく使われる)について「Fisher's exact testならば正確であり、カイ二乗検定はその近似に過ぎない」というようなデタラメな解説が横行していることにも出ている。
論文でそれを正しく指摘している人がいても理解できない人達が沢山いる。
タグ:
posted at 16:55:29
p値を計算するためには、帰無仮説の数学的なモデルとしての確率分布を与える必要があるのですが、2×2の分割表における独立性の帰無仮説に対応する確率分布は(周辺度数が全て固定されているという普通はありえない場合を除いて)1つ以上のパラメータの不定性があります。
タグ:
posted at 17:03:15
「数学的モデルをデータに基いて評価する」という視点があれば、2×2の分割表の独立性の帰無仮説の数学的モデル化がただ1つに決まらないという問題にすぐに気付いて、「Fisherの正確確率検定は正確である」という主張の危うさにノータイムで気付くはずなのに、全然そうなっているように見えない。
タグ:
posted at 17:05:58
私は
どんなに優れた人であっても結構致命的にトンデモに騙されているものだ
と言うことを好むのですが、「2×2の分割表に関するFisherの正確確率検定は正確である」と信じている研究者達はその典型例とみなせると思っています。
集団でいるのでちょっと怖い。
タグ:
posted at 17:08:58
「数学的モデルをデータに基いて評価する」という科学における基本中の基本である考え方に忠実であれば騙されることがないはずのことなので、騙されていたことに気付いた研究者は心が痛むはずだと思う。
おそらく教科書などの権威に心が負けていたせいで騙されてしまった。
タグ:
posted at 17:12:21

大学1年の時に一般教養で民俗学を履修した。
一発目の授業で先生が
「この中で地方出身者の人挙手して」
と言ったので素直に挙手したところいきなり当てられ、出身県を尋ねられた。
これも素直に「群馬です」と答えたところ、「君んちは古い家系?」と尋ねられ、「まあ割と」と答えた。
タグ:
posted at 17:26:31
すると先生は黒板にサラサラと略図を描き、
「君んち、大体こんな感じでしょ?
まず家の北西に防風林、その手前に家神様の祠、これは多分お稲荷さんかな、そしてその反対、南東の方角にひょっとしたら馬頭観音を祀った碑があるかも。
違う?」
と。
完璧だった。
教室は激しくざわついた。
タグ:
posted at 17:30:38
先生は教室が静まるのを待ち、
「皆さんは民俗学なんて得体の知れない、役に立たない学問だと思ってるかもしれないけど、こういう事ができるのが民俗学という学問です。
これから1年間、よろしくお願いします」
と微笑んだ。
未だにこれは最高の自己紹介であり最高の授業の始め方だったと思っている。
タグ:
posted at 17:33:27

済州島のカルマン渦列,動画にすると渦たちがウズウズしているのがよくわかり,自然現象としての地球流体力学の美しさを堪能できるのでぜひ見てください. pic.twitter.com/1SAGbMyBqc
タグ:
posted at 17:34:57
なんで馬頭観音かと言うと、群馬で古い家は大体養蚕農家だったことが多いからです(馬頭観音は家畜の守り神。蚕も立派な家畜の一種)
ついでに言うと、防風林を構成する樹種の中に桑が多いこともピタリと言い当てられました。
タグ:
posted at 17:39:41
非公開
タグ:
posted at xx:xx:xx
非公開
タグ:
posted at xx:xx:xx
非公開
タグ:
posted at xx:xx:xx
非公開
タグ:
posted at xx:xx:xx
非公開
タグ:
posted at xx:xx:xx
@tabunmori どういう本を読めばいいのかはわかりません。私は自分の数学的および科学的素養を使ってほとんど自分で考えて結論を出しました。
以前、大学2年生向けとして使用可能そうな統計学の教科書を色々チェックしてみたことがあるのですが、正直、自分で使う気になれるものは見つかりませんでした。
タグ:
posted at 18:27:38
@tabunmori 渡辺澄夫著『ベイズ統計の理論と方法』は個人的に読みました。
しかし、この本はよほどの数学的な実力抜きには読めそうもない本だし、統計学の実践的な使い方に関する本でもないので、数学好きな人以外にはすすめ難いです。
タグ:
posted at 18:31:37
@tabunmori 統計学は非常に残念なことに「お墨付きを得るための道具」であるかのように使われることが浸透していて、大学の学部での統計学の授業もそれに合わせた内容を教える雰囲気になっています。
そういう雰囲気で勉強するときちんと批判的に統計学を勉強することは無理だと思います。
タグ:
posted at 18:33:32
@tabunmori 統計学とは全然無関係に、正しい考え方をするための素養(数学的な実力は必須)を身に付けて、自分で論理的に再構成できたこと以外は信用しないという態度を取り続けることを数年~10年以上続ければ、統計学についても色々理解できるようになると思います。
タグ:
posted at 18:35:44
@tabunmori 数学的モデルの評価の仕方の基本は
(1) 数学的モデル内で何が起こるかを計算できるようにしておく。
(2) 現実世界から得たデータとそれを比較してみる。
(3) あまりにも一致しなければその数学的モデルで現実世界を近似的に説明できるという仮説は疑わしいと考える。
です。統計学でも同じ。
タグ:
posted at 18:37:54
@tabunmori (1) 帰無仮説の数学的モデル化としての確率分布を適切に設定し、その確率分布に関する確率を計算できるようにしておく。
(2) 現実から得たサンプル以上の偏りがそのモデルの確率分布で起こる確率(p値と呼ばれる)を計算してみる。
(3) その確率(p値)が小さいならば帰無仮説は疑わしいと考える。
タグ:
posted at 18:40:13
@tabunmori 上で、「統計学についても色々理解できるようになると思います」と安易に書いてしまいましたが、実際には誤解の連続でそれを常に訂正し続けることになります、私の経験では。
どの段階でも、自分が完璧に理解しているという感覚は得られない。
タグ:
posted at 18:41:44
非公開
タグ:
posted at xx:xx:xx
@tabunmori 現実世界で得たデータと数学的モデル内での計算の一致度を見るときには要注意なことがあって、数学的モデルを複雑にしまくれば適当にパラメーターを調節していくらでもデータに一致するようにできることです。続く
タグ:
posted at 18:46:18
@tabunmori しかし、統計学ではその辺のことは赤池弘次さんによってある程度解決済み。大体において複雑なモデルほどデータに合わせたフィッティングの結果の予測性能は下がります。そういう意味での予測性能の適切な推定方法を赤池さんは考えました。それがAICです。
タグ:
posted at 18:48:45
@tabunmori AICなどの予測分布の汎化誤差の推定値としての情報量規準については、渡辺澄夫著『ベイズ統計の理論と方法』に詳しく書いてあります。この本の売りはモデルの正則性を仮定しないベイズ推定の場合に適切な情報量規準を与えていることです(WAIC)。
この辺の話は個人的な意見では極めて基本的。
タグ:
posted at 18:50:45
@tabunmori 基本的ですが、数学的にはかなり高級な話題になってしまいます。
しかし、「モデルを複雑にすればどんなデータにもフィットさせることができるだろう」のようなくだらない話に深刻に付き合う必要がないことを確信できるようになるという意味で、非常に基本的な話だと思います。
タグ:
posted at 18:52:36
非公開
タグ:
posted at xx:xx:xx
@tabunmori 統計学のための数学的素養としては、
* 大数の(弱)法則
* 中心極限定理
* Kullback-Leibler情報量に関するSanovの定理
あたりが基本的なのですが、私が書いた(謙遜ではなくあまりよくなさそうな)解説が以下の場所にあります。
genkuroki.github.io/documents/Intr...
genkuroki.github.io/documents/2016...
タグ:
posted at 18:55:24
@tabunmori Sanovの定理は各種確率分布について理解するときに基本的なイメージを与えるという意味で非常に大事なのですが、解説が見当たらないので自分が書きました。
渡辺澄夫著『ベイズ統計の理論と方法』の内容の一部を初等化して簡単にしたければ次のリンク先を読むとよいです。
genkuroki.github.io/documents/2016...
タグ:
posted at 18:59:21
非公開
タグ:
posted at xx:xx:xx
非公開
タグ:
posted at xx:xx:xx
非公開
タグ:
posted at xx:xx:xx
非公開
タグ:
posted at xx:xx:xx

高校生たちの研究の審査した機会が昨年の夏あったが、ランダムサンプリング、統計検定、予測モデルの理解が大切だと感じたのだった。 twitter.com/katzkagaya/sta...
タグ:
posted at 19:33:51
非公開
タグ:
posted at xx:xx:xx


【教えて君】中学生(ないし小学生)向けの球の表面積ないし体積の(できるだけ簡単な)求め方。「紐を巻いてみたら4倍になった」とか「水を入れたら…」とか実験的な「証明」は無しで。一方がわかればもう一方は「球は中心を頂点とする錐体の集まり」で求まるとして、同じぐらいのレベルで…
タグ:
posted at 20:37:00
@tabunmori 赤池さんが「エントロピー」と呼んでいるものが(符号と定数差の違いを除いて)KL情報量と同じものです。
尤度(ゆうど)(の対数)の概念がどうして有効かを理解するためには必須。
しかし、普通の統計学の教科書に「尤度」は出て来ても赤池さんがしているような説明はない。
twitter.com/genkuroki/stat...
タグ:
posted at 20:54:03

俺の実装したMINIXが1時間でクラッシュする
やけになってPCエミュレーターまで実装した
エミュレーター上では完璧に動作した
生徒にぼやいたところ、8086は熱くなると割り込み15かけるよ
そんなのドキュメントにないぞ!
www.minix3.org/conference/201...
タグ:
posted at 21:23:17

@esumii www.quora.com/Geometry-What-...
こちらはまだ工夫次第で教えられるのかなと思います。もしご存知なければご確認ください。
球と、それをちょうど包む円柱の表面積が一致するということに注目した証明です。
タグ:
posted at 21:23:19
大数の法則より、確率分布q(y)に従うサンプルY_1,…,Y_nの対数尤度の-1/n倍
-(1/n)Σ_{i=1}^n log p(Y_i)
はn→∞で汎化誤差
-∫ q(y) log p(y) dy
に収束します。汎化誤差はKL情報量
D(q||p) = ∫q(y)log(q(y)/p(y))dy
とp(y)について定数差の違いしかない。Sanovの定理から~続く
タグ:
posted at 21:37:28
~、KL情報量D(q||p)は分布pによる分布qのシミュレーションの「誤差」とみなせるので、汎化誤差が小さなpの方がqをよりよくシミュレートしてくれる。
pの対数尤度の-1倍は、汎化誤差の推定値になっているので、尤度が大きなpを見つけることは汎化誤差が小さなpを見つけることに繋がる。
タグ:
posted at 21:41:00

@ohashihirofumi もう一個探してきました 盤面全体映ってないけどよろしくお願いします
ハンターハンターのアニメで2013年に放送されたようです
igoarekore.blogspot.com/2013/11/hunter... pic.twitter.com/djs3odxg0M
タグ:
posted at 21:44:05
これが、最尤法の基本。
そして、汎化誤差は複雑なモデルほど小さくなりにくい傾向を持つので、その分の補正を入れると、AICやWAICなどの対数尤度の-1倍よりも精密な情報量規準が得られる。
こういうわかりやすいストーリーを説明してくれると「尤度って何?」を理解しやすいと思う。
タグ:
posted at 21:44:08
赤池さんの1980年の論説は20世紀の統計学の偉人達をめった斬り(笑)
* 最尤法の開発者であるフィッシャーさんも尤度の概念を十分に理解していなかった。
* 「頻度論vs.ベイズ」という対立図式を描いた20世紀のベイズ統計の偉い人たちはベイズ統計を理解してなかった。
twitter.com/genkuroki/stat...
タグ:
posted at 21:52:37
1980年の時点で赤池さんが色々啓蒙活動をしていたのに、
* 尤度の概念を汎化誤差との関係で理解すること
*「頻度論vs.ベイズ法」という対立図式がナンセンスであること
などが、大学教育には全然浸透しなかった。
タグ:
posted at 21:56:25
非公開
タグ:
posted at xx:xx:xx
非公開
タグ:
posted at xx:xx:xx

UFO教授 (藤木文彦 Fumihiko @UFOprofessor
@genkuroki @sekibunnteisuu 本当は、大学数学の基礎として高校数学があり、(以下略)そして人間社会のために全ての数学がある、のだとおもいますが。残念ながら今の算数数学は教師のためにあるように思えます。
タグ:
posted at 21:59:25
非公開
タグ:
posted at xx:xx:xx

@YumeayaAnesan 失礼します。九九の表を負の数にまで延長すれば分かるかと思いますが。
twitter.com/genkuroki/stat...
タグ:
posted at 22:02:41

難易度が高い。とりあえず囲碁に詳しくない人が総譜を取り寄せて忠実に再現したことは分かるので有名な対局なのだろう…これまたフォロワーの皆さんに助けを求める展開。m(__)m twitter.com/serumu1/status...
タグ:
posted at 22:09:57

コーシーの定理だけで exp(z)/z の周回積分を求める.
パズルのような経路変形が楽しいので GIF にしました.
この変形は,いわゆるホモローグの考え方にもつながるものです.
じっくり見たい場合は neqmath.com/2019/01/21/exp... pic.twitter.com/qqRci7bRsi
タグ:
posted at 22:15:29
情報量統計学って本、北大の動物生理の院生室にあったのを見つけて、ちょっと古いけどこれはいい本では?って思っていたけど、やっぱりいい。goo.gl/images/mCewV6 pic.twitter.com/ji80rKWKXc
タグ:
posted at 22:28:50
英訳もされてるなということで、そのときしたメモ。日本語で読めるから必要ないかもですが、英語圏の論文のために引用するのもアリかということで。 pic.twitter.com/SqNhmHYcaR
タグ:
posted at 22:48:12
@tabunmori 対数尤度の-1倍とKL情報量の関係は大数の法則から出て来て、KL情報量の意味はSanovの定理からわかり、対数尤度の-1倍の赤池情報量規準AICへの精密化には(ある意味で大数の法則の精密化になっている)中心極限定理を使います。
大数の法則、Sanovの定理、中心極限定理の3つが理解の鍵になっています。
タグ:
posted at 22:54:01
* 大数の法則
* 中心極限定理
* KL情報量に関するSanovの定理
は独立同分布確率変数列に関する統計学を基礎付けるための
三種の神器。
学部生向けの統計学の教科書ではなぜかSanovの定理については一切触れようとしない。結果的に尤度の概念が理解不能になる。
タグ:
posted at 22:57:53

@serumu1 @ohashihirofumi www.101weiqi.com/chessbook/ches...
王立誠九段対趙善津九段らしいですね、結果も黒(王立誠九段)の五目半勝ちです
タグ:
posted at 23:00:06

「進次郎氏は「その(落合氏が出馬する)時、落合クンが自分の知識、知見を発揮できるようなところは自民党だと言われるような、自民党でありたい」と話した」
落合陽一氏「今の仕事やり終わったら」政界進出意欲 www.nikkansports.com/general/nikkan...
タグ:
posted at 23:02:01

落合陽一が与太を飛ばすのは自由だけど、最近知った様々な言動からすれば、政治家にしてはいけないタイプ。とりあえず、「君のお金はどこに消えるのか」を読むべき。マンガだから、すぐ読める twitter.com/y_kurihara/sta...
タグ:
posted at 23:06:58

人間として、という話をとりあえず置いたとして、マスメディアの責任ある立場としてこれを言うのか.このツイートでより多くの健康被害が出た場合、その責任を受けとめる覚悟はあるのか
タグ:
posted at 23:09:43
#数楽 Cauchyの積分公式とSchwartz超函数としてのδ函数の定義を比較すれば、複素函数でデルタ函数を実現できそうなことがわかる。そういう話は昔からよく知られていたが、一般論は佐藤超函数(hyperfunction)の理論として構築された。
twitter.com/genkuroki/stat...
タグ: 数楽
posted at 23:13:48
#数楽 コンピューターで佐藤超函数ごっこをして遊べることが
nbviewer.jupyter.org/gist/genkuroki...
nbviewer.jupyter.org/gist/genkuroki...
を見ればわかる。 #Julia言語 pic.twitter.com/r62ZruDdEY
posted at 23:13:52


夫が相対性理論について熱く語ってくれてるが、妊婦はあまり頭に血が回ってないので小難しい話はしてくれるなと言った。が、特にリアクションなくそのまま話し続けるので、ああ別に私が聞いてるとか聞いてないとか関係ないんだと分かって寝室に移動して洗濯物たたみ始めたらついてきた。なんなの。
タグ:
posted at 23:42:24
非公開
タグ:
posted at xx:xx:xx
