
黒木玄 Gen Kuroki

- いいね数 389,756/311,170
- フォロー 995 フォロワー 14,556 ツイート 293,980
- 現在地 (^-^)/
- Web https://genkuroki.github.io/documents/
- 自己紹介 私については https://twilog.org/genkuroki と https://genkuroki.github.io と https://github.com/genkuroki と https://github.com/genkuroki/public を見て下さい。
2021年09月21日(火)

Little #julialang throwback this morning scrolling thru old photos. Highlights: *prerelease* of version 0.3, running Julia repl in a sublime text editor pane (#rip sublime-ijulia), probably the earliest time zones work that ever occurred in Julia. pic.twitter.com/zBHyD1H7Xn
タグ: julialang
posted at 00:28:03

@OokuboTact #統計 三中さんは学生に向けて事前分布について答えて曰く【「美しくない」!「美しくない」!「美しくない」!— 大事な点なので三回繰り返しました】
さすがに学生へのこのコメントは非難されて当然の行為だと思いました。
統計学教育については詳しくなればなるほど残念な話に気付く感じ。😭 twitter.com/genkuroki/stat... pic.twitter.com/BDjZXWWgdv
タグ: 統計
posted at 00:34:08
@OokuboTact #TodaiStat というタグが付いていることから、東大の学生さんが被害にあっていることが分かります。
同じ日本人なのに、赤池弘次さんとか渡辺澄夫さんとかの素晴らしい見解や研究が、ベイズ統計教育で無視されている感じ。2人とも世界的に論文がめっちゃ引用されている。
何がどうなっているんだか。
タグ: TodaiStat
posted at 00:41:57
@OokuboTact #統計 事前分布(先験分布)の利用について
40年以上前の赤池さん曰く【データよりパラメタが多くても推定できるのですよ】
現代の三中さん曰く【「美しくない」!「美しくない」!「美しくない」!— 大事な点なので三回繰り返しました】
比較すること自体が不当な感じ。赤池さんの話は真に面白い。 twitter.com/genkuroki/stat...
タグ: 統計
posted at 00:49:55

新しい記事がQiitaにアップされました!#Julia言語 #Julia日本語記事
qiita.com/StrawBerryMoon...👈
タグ: Julia日本語記事 Julia言語
posted at 01:23:31

Hideki Kawahara: WAS @hidekikawahara
ただし、仕込みが長いのが欠点。EGG音声データベースの840文章の処理に12時間かかるし、結果は80GBになる。そろそろ真面目にJuliaにお願いするべきか?明日の午後には計算が終わっているので、とりあえずは困らないし、計算は、M1 Macminiにまかせてあるので、MacBookProを使う仕事には支障はない。 twitter.com/hidekikawahara...
タグ:
posted at 01:48:36

ごまふあざらし(GomahuAzaras @MathSorcerer
PIL さん偉大では???
#Julia言語 pic.twitter.com/5hF2YHYCTo
タグ: Julia言語
posted at 02:59:34

Dr. Chris Rackauckas @ChrisRackauckas
Lots in #julialang #sciml this week! We are excited to share "Stiff neural ordinary differential equations" has been published at Chaos.
aip.scitation.org/doi/10.1063/5....
The core take away from the paper: using a stiff ODE solver is not enough! You have to change the adjoint method too!
posted at 03:23:47
Dr. Chris Rackauckas @ChrisRackauckas
One problem is that stiff ODEs are not easily reversible, even with stiff ODE solvers. While lack of reversibility of ODEs has been a known issue, when does it apply? This manuscript shows how stiffness => a large Lipschitz constant and thus you know it won't reverse!
タグ:
posted at 03:23:47
Dr. Chris Rackauckas @ChrisRackauckas
You can take a widely used and stable stiff ODE solvers like CVODE and run it forward -> reverse on a stiff ODE like ROBER and show it it noticeably diverges when going in reverse, even if it would analytically go back on the same path. Oops! pic.twitter.com/mW7eCd16VI
タグ:
posted at 03:23:48
Dr. Chris Rackauckas @ChrisRackauckas
We show that this error propagation grows exponentially with the Lipschitz constant, which is like 10^9 or 10^10, so reversing is just a no-go on stiff ODEs. pic.twitter.com/RaKTu5BOvW
タグ:
posted at 03:23:49
Dr. Chris Rackauckas @ChrisRackauckas
But is there anything else you have to worry about with stiff ODE adjoints? Yes! The problem with stiff ODEs is that their solving cost is not linear with the number of ODEs. Generally it's cubic due to linear solver cost! pic.twitter.com/5ofoDiRvJl
タグ:
posted at 03:23:51
Dr. Chris Rackauckas @ChrisRackauckas
(sans Newton-Krylov techniques, but GMRES does not converge fast with stiffness without preconditioning away the high conditioning of the Jacobian. That's a whole story on its own that is a deep deep thing to explore, but preconditioning is problem-dependent)
タグ:
posted at 03:23:51
Dr. Chris Rackauckas @ChrisRackauckas
Why is this a problem? Current adjoints for neural ODEs solve a O(2*states + parameters) sized system, so the cost is O((states+parameters)^3)! Cubic cost in the number of weights of a neural network is not good! It's so slow that you can't really even test it well! pic.twitter.com/D6KvLxsmvQ
タグ:
posted at 03:23:53
Dr. Chris Rackauckas @ChrisRackauckas
We identified 3 ways to mitigate this issue: a split reversing adjoint call QuadratureAdjoint which is O(states^3 + parameters) (much better!), use an IMEX integrator to treat the explicit integral of the parameters with explicit integrators (also O(states^3 + parameters), or... pic.twitter.com/WYfU2oSyyg
タグ:
posted at 03:23:54
Dr. Chris Rackauckas @ChrisRackauckas
you can also even accelerate it by splitting and parallelizing over forward-mode AD passes. That's right, O(p n^3) < O((n+p)^3) for large p, so p passes of one derivative at a time can also lead to asymptotically decreased costs! That's a fun little tidbit.
タグ:
posted at 03:23:55
Dr. Chris Rackauckas @ChrisRackauckas
Fast parallelized forward-mode can be found in #julialang Polyester.jl BTW.
github.com/JuliaSIMD/Poly...
タグ: julialang
posted at 03:23:55
Dr. Chris Rackauckas @ChrisRackauckas
Then you do some rescaling to handle the ill-conditioning of the Hessian... pic.twitter.com/z4TwnWfZoZ
タグ:
posted at 03:23:56
Dr. Chris Rackauckas @ChrisRackauckas
And boom, problems which were previously too unstable and too computationally costly to train are the demonstrations we use to end the paper. Tada! pic.twitter.com/vxVhY8m6v8
タグ:
posted at 03:23:57
Dr. Chris Rackauckas @ChrisRackauckas
Is that all this week? No! A follow-up #julialang #sciml paper was also published for IEEE HPEC this week! This one is an update of a previous preprint on benchmarking adjoint techniques. The arxiv version is arxiv.org/abs/1812.01892. Tons of benchmarks!
posted at 03:23:57
Dr. Chris Rackauckas @ChrisRackauckas
tl;dr of this second paper: forward-mode AD is the right choice until 50 ODEs, at which point static VJP (Enzyme.jl) takes the candle due to better asymptotic properties.
タグ:
posted at 03:23:57
Dr. Chris Rackauckas @ChrisRackauckas
That first result in more detail: forward-mode AD (via ForwardDiff.jl #julialang) is legit. How legit? Yes you can implement forward sensitivities by hand, but it doesn't even come close. It turns out that the compiler transforms can fuse much better and generate more SIMD. pic.twitter.com/7okHHia583
タグ: julialang
posted at 03:23:58
Dr. Chris Rackauckas @ChrisRackauckas
Thus if <50 ODEs, we have found across many different modeling domains that direct forward-mode AD is the best implementation of the derivative/gradient calculations.
タグ:
posted at 03:23:58
Dr. Chris Rackauckas @ChrisRackauckas
But to identify what happens on big equations, we used a common stiff PDE benchmark problem (the Brusselator), and it showed a wealth of information in just one plot. First of all, notice that the asymtopically-better QuadratureAdjoint is by far the fastest here! In log scale! pic.twitter.com/pPPTBdJSzg
タグ:
posted at 03:23:59
Dr. Chris Rackauckas @ChrisRackauckas
But this simultaneously highlights the importance of reverse mode AD. When you write down the adjoint equation you have to calculate a vector-Jacobian product. If you have reverse-mode AD integration, then this can be done in one forward/backwards pass without generating the jac. pic.twitter.com/HBn1Q7LfET
タグ:
posted at 03:24:00
Dr. Chris Rackauckas @ChrisRackauckas
This has been known, but it's a benchmarking paper so let's establish... how much does it really matter? Look again: it's about 2-3 orders of magnitude of a performance advantage by doing this *correctly*.
タグ:
posted at 03:24:01
Dr. Chris Rackauckas @ChrisRackauckas
So look at that image again. The purple performance line is the "calculate the Jacobian, invert, and then J'v" implementation of the interpolating adjoints, i.e. the same technique as CVODES. Algorithmically, this is 2-3 orders of magnitude slower than QuadratureAdjoint + vjp. pic.twitter.com/Um1Qdi79Sd
タグ:
posted at 03:24:01
Dr. Chris Rackauckas @ChrisRackauckas
But why *correctly*? Because how you calculate the vjp matters a ton. Using a dynamic reverse mode AD system (ReverseDiff.jl, very similar to PyTorch or TensorFlow Eager) does not help all that much. Statically compiling that vjp improves by an order of magnitude. Enzyme another. pic.twitter.com/5XcU3tBISK
タグ:
posted at 03:24:02
Dr. Chris Rackauckas @ChrisRackauckas
If you're curious why Enzyme is so helpful here, it's because it's mixing the LLVM optimization passes with the AD codegen and generating a code that is optimized for the forward+backwards pass together. This allows it to be fully non-allocating. See arxiv.org/abs/2010.01709
タグ:
posted at 03:24:03
Dr. Chris Rackauckas @ChrisRackauckas
Note that this last result applies to heavily nonlinear scalar codes (PDEs, large systems of DAEs, etc.), but not necessarily to large neural ODEs where the ODE operations are all just big vectorized function calls. The vjp really matters if it's tons of little functions.
タグ:
posted at 03:24:03
Dr. Chris Rackauckas @ChrisRackauckas
But the moral of the story is, optimizing adjoints for the models engineers really solve (big nonlinear stiff DAE/PDE systems) has been a multi-year process requiring similar detailed touches as implementing a DAE solver. The simpler non-stiff ODE tested methods don't apply.
タグ:
posted at 03:24:04
Dr. Chris Rackauckas @ChrisRackauckas
With the latest releases, #julialang #sciml uses these results in a polyalgorithm to automatically switch between forward and adjoint techniques, along with switching the vjp method and which adjoint is used. Similar to using A\b, we compiler analyze and do it automatically. pic.twitter.com/O4gUryvDBV
posted at 03:24:05

🚀 I wrote a blog post on the stochastic block model for generation of graphs with community structure.
code in Julia. #julialang
simonensemble.github.io/pluto_nbs/stoc... twitter.com/gabrielpeyre/s... pic.twitter.com/P1cuscmxsT
タグ: julialang
posted at 03:39:36
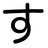
twitter.com/esumii/status/... 「1+1は2です」と教えてから「2は何ですか?」「2はどんな数をもとにしていますか?」と聞くようなもの。
タグ:
posted at 06:37:47
@toukei_er #統計 Rのfisher.test (およびbinom.test) が表示するP値と信頼区間に整合性がないことについては、私も繰り返し解説しています。
ツイログの検索
↓
twilog.org/genkuroki/sear...
実際に自分で実装して確認したりもしています。
タグ: 統計
posted at 07:07:58

Mathematics, chaos, beauty.
Physics PhD candidate Ben Bartlett (@bencbartlett) writes, "It's called the Lorenz 𝘢𝘵𝘵𝘳𝘢𝘤𝘵𝘰𝘳 because all nearby points are 𝘢𝘵𝘵𝘳𝘢𝘤𝘵𝘦𝘥 into the set of chaotic orbits, regardless of initial conditions." Source: bit.ly/3lFoEpD pic.twitter.com/rzMVzkByBL
タグ:
posted at 07:22:31
@toukei_er #統計 P値と信頼区間の関係については、それらの背後にあるP値函数をプロットすると分かりやすくなります。
P値函数=パラメータにP値を対応させる函数
私のツイログを検索
↓
twilog.org/genkuroki/sear... twitter.com/genkuroki/stat...
タグ: 統計
posted at 07:33:13
「この手法はベイズらしくない」的な査読コメント‼️
現代において頻度論とベイズ主義の対立と言う場合には「互いに喧嘩をしている」ではなく、「互いに水と油だと思っている人達がいる」というニュアンスだと思う。
例えば、標本分布を使った途端に「それベイズじゃない」と言うおかしな人達の存在。 twitter.com/hmkz_/status/1...
タグ:
posted at 08:21:49
@toukei_er #統計
* P値函数
* 有意水準α
* (帰無仮説の)P値
* 信頼区間
の関係。異なるP値函数に関するP値と信頼区間は整合性がなくなる。
P値函数を沢山プロットすると、百聞は一見に如かずで理解が進む。 pic.twitter.com/hvNEYvX2KY
タグ: 統計
posted at 08:34:03

 非公開
非公開
タグ:
posted at xx:xx:xx
非公開
タグ:
posted at xx:xx:xx

Creating your own vector type in #JuliaLang. pic.twitter.com/ZZgHb2e7Hj
タグ: JuliaLang
posted at 09:27:22

昨日のこれについて「え〜、それ困る〜〜」という声がたくさん来ているんですが、何人かの方からコメントいただいているように、回避方法はあるようですのでコメントを参照ください(私は自分では試してないです)。
タグ:
posted at 12:26:50
#Julia言語 私が知る限りにおいて、手動でマージンを設定するしかない感じ。
Plots.jlは大量のバックエンドを抱えていて、バックエンド側でどうなるかを任意の場合に自動で完璧にコントロールするのは難しそう。 twitter.com/natsulait/stat...
タグ: Julia言語
posted at 12:29:57
@BluesNoNo #統計 普通の常識では、
Aと仮定したときにBが導かれる
という数学的結果を、様々な「誤差」が伴う現実に適用する場合には、
Aに近い状況のもとでBに近いことが成立する
の形式で使用するのが普通だと思います。
I=Jという数学的仮定は、現実への応用時にはI≈Jに緩められ、誤差が増える。
続く
タグ: 統計
posted at 12:59:50
@BluesNoNo #統計 真の分布qがモデルp(x|w)によってq(x)=p(x|w₀)書けているという仮定は、現実への応用ではq(x)がp(x|w₀)で近似されているという仮定に緩められる。
数学的にぴったり〜となると仮定して定理を証明してあっても、現実への応用でその「ぴったり」の仮定が成立していると思う必要は全然ない。続く
タグ: 統計
posted at 13:02:55
@BluesNoNo #統計 実際の計算例
サンプルを生成している分布がGamma(20, 1/20)のときに、3種類の正規分布モデルで最尤推定し、AICでモデル選択した場合。
この場合には未知の真の分布は推定用のモデルの正規分布には含まれていない。続く
github.com/genkuroki/publ...
#Julia言語 pic.twitter.com/wcaOJMoRI0
posted at 13:05:45
@BluesNoNo #統計 しかし、未知の真の分布は結構正規分布に近い。
添付画像のグラフはAICによるモデル選択で選択された各モデルの割合です。
上段は真の分布がガンマ分布で、下段は比較用の真の分布が正規分布の場合です。その2つの間の違いはかなり小さくなっています。続く
github.com/genkuroki/publ... pic.twitter.com/lKetG4mbH2
タグ: 統計
posted at 13:08:48
@BluesNoNo #統計
normal0 = 真の分布と同じ平均と分散を持つ正規分布 (パタメータなし)
normal1 = 真の分布と同じ平均を持つ正規分布 (パタメータは分散の1つ)
normal2 = 正規分布 (パラメータは平均と分散の2つ)
normal0は汎化誤差が最小のモデルになっている。
github.com/genkuroki/publ... pic.twitter.com/6wDkE35AO9
タグ: 統計
posted at 13:13:09
@BluesNoNo #統計 理想的には常に汎化誤差が最小のモデルnormal0が選択されて欲しいのですが、パラメータがある場合にAICと汎化誤差は逆相関するので、確率的にかなり失敗する。続く
github.com/genkuroki/publ... pic.twitter.com/k6DfLFd1pb
タグ: 統計
posted at 13:17:09
@BluesNoNo #統計 しかし、3つのAIC同時比較するモデル選択では半分以上の場合にnormal0が選択され、1対1の勝負ならnormal0は6割以上の確率で他の2つに勝つ。
パラメータ数の少ないnormal1も6割以上の確率でnormal2に勝つ。
続く
github.com/genkuroki/publ... pic.twitter.com/YHLvr4C1RG
タグ: 統計
posted at 13:18:45
@BluesNoNo #統計 そして、今の場合にはGamma(20, 0.05)が結構正規分布に近いお陰で、真の分布がGamma(20, 0.05)の場合と真の分布が正規分布の場合での違いは小さい。
この場合にはAICが使用可能な前提条件がぴったり成立しているわけではないが、AICは十分に実用的だと考えられる。
github.com/genkuroki/publ... pic.twitter.com/ANs1gc7cVW
タグ: 統計
posted at 13:21:18
@BluesNoNo #統計 こういう計算例を知っていれば、添付画像のような【ここでAICを使うことはI=Jを信じていると言えるか?】のような問いを発すること自体が、数学の通常の使い方に関する無知丸出しな発言であることもわかります。
適当な「誤差」が入って来ても大丈夫な数学的道具を使っているという認識が大事。 pic.twitter.com/LAVxCy7Wod
タグ: 統計
posted at 13:27:02
@BluesNoNo #統計 「正規分布モデルを使って平均の信頼区間を計算した人は、母集団分布が正規分布になっていると信じていると言えるのか?」という問いもピント外れだと思います。
問うべきなのは「母集団分布が正規分布からどれだけ外れていてもその方法の誤差が実用的範囲内におさまるのか?」です。
タグ: 統計
posted at 13:33:56

とうとう、アメリカにおける新型コロナの死者数が、
100年前に起こったスペイン風邪の死者数を超えました。
まさか現代の超大国でこんなことが起こるなんて…… twitter.com/spectatorindex...
タグ:
posted at 13:44:02
@you_you_1 goo国語辞典やデジタルデジタル大辞泉の執筆者も、算数教育における「立式」の意味を知らなかったのでしょう。
私が辞書に載せるなら、
1. [特殊な算数教育用語] 算数の文章題の「式 答え 」形式の解答欄の式の項目に書いて正解になる式を作ること。
2. 式を作ること。
のように分けます。続く
タグ:
posted at 14:36:55
@you_you_1 文脈によっては「立式」を単に「式を作る」の意味で使っても無害な場合もあります。
しかし、算数教育に関する話題で、しかも「立式」を特殊な意味で使っている可能性の高い教育関係者との議論の文脈で、単に「式を作る」の意味で使うのは非常にまずいです。
その点を反省するべきだと思いました。
タグ:
posted at 14:40:01
@you_you_1 100年近く前から、「立式」という用語には特殊なニュアンスが込められていた証拠が以下のリンク先にあります。 twitter.com/genkuroki/stat...
タグ:
posted at 14:44:31

「母はこの問題の意味を理解できませんでした…」小学3年生の子どもが解けなかった算数の問題は大人でも回答に詰まってしまう - Togetter togetter.com/li/1777428 @togetter_jpより
タグ:
posted at 14:46:40
@you_you_1 今後は「現実の問題から立式することを子供に課す教育は極めて有害である。なぜならば~」と正確に説明した方がよいと思います。
「立式」という用語をどうしても使いたいなら、算数教育界で有害教育の推進のために使われている用語であることについてもきちんと説明した方が良いでしょう。 pic.twitter.com/ljTrrcfYO6
タグ:
posted at 14:49:03
#超算数 手元にある小3の算数の教科書のデータの大きな数を扱う節の部分をチェックしてみました。
一生理解する必要がない「どんな数をもとにすると」という言い回しは発見できませんでした。
内容的に最も近いものを添付画像に引用。
「どんな数をもとにすると」とは相当に印象が違う感じ。 pic.twitter.com/HVkOvDWVXb
タグ: 超算数
posted at 15:00:52

@genkuroki 東京書籍2020は、文脈は十分にはわかりませんが、そっくりなのがあるそうです(黒木さんは通常ブロックを推奨してるアカウントなことは承知ですがここは画像データありなので)。 twitter.com/flute23432/sta...
タグ:
posted at 15:07:34
先程RTしたように、2020年の東京書籍の教科書には以下のような記述があるらしいです。これはひどいな。
子供にどう見えているかは、ページ丸ごとを見ないと十分に分からないので、ページ丸ごと見せてくれる人がいると助かります。 pic.twitter.com/zTI8tA1p00
タグ:
posted at 15:13:02
特に「もとにする数」の説明が東京書籍の小3上の算数教科書でどうなっているかを知りたい人は多いと思います。
小5算数教科書の割合の章には「もとにする量」「比べ(られ)る量」という用語が出てきます。そして、それらの用語の使用に児童が困難を覚えることが、算数教育の研究で知られています。
タグ:
posted at 15:17:15
要するに小5での割合教育で一生理解する必要がなくて児童もよく理解できない悪名高い用語である「もとにする量」「比べ(られ)る量」を使うだけではなく、小3で「もとにする数」という用語を使い始めた。
どうしてこういう子供に優しくない教え方をしたがるのか?
タグ:
posted at 15:20:09

@genkuroki 我が家も「超算数」的な問題は「これはできなくてあたりまえ、ただ計算結果とか答えがわかってるお前はすごい!」で流すようにしてます。
数学の解き方を理不尽なやり方に限定する教育には与することはできません
タグ:
posted at 15:25:30
算数プリントの問題は大抵つまらないのですが、たまに面白い問題(パズル)がおまけで載っていたりします。
家庭内みんなで解き始めるというようなことになれば、きっとその問題を載せた人もうれしいと思う。
大人の事情が色々ありそうなところで、面白いおまけ問題を載せてくれてありがとう! twitter.com/genkuroki/stat...
タグ:
posted at 15:45:23
@genkuroki うちはリアルタイムですので「これわかんないよ!僕でも悩むわ!」で笑い飛ばすことを意識してます。ただ娘に「で、結局この問題って、なに聞いてるの?」と聞かれたら、なるべく「問題の意図」と「どう答えてほしいか」を批判的に紹介した上で、できる限り「一般解」へとつなげるようにしています
タグ:
posted at 15:46:40
資料追加
ten.tokyo-shoseki.co.jp/text/shou/sans...
東京書籍のパンフレット
より。添付画像②に
【どんな数をもとにすると3+4の計算で考えることができますか。~
① 0.3+0.4 ② 30+40 ③ 300+400】
と書いてあります。
どうしてわざわざ児童が困ることが前もって分かっている言い回しを使うのか? pic.twitter.com/nEd3WX4i24
タグ:
posted at 16:05:52
どうしてわざわざ児童が困ることが前もって分かっている言い回しを使うのか?
算数教育界にそういう伝統があるから。
小2でのかけ算導入で使われている「4この2つ分」というフレーズの意味を理解している児童は5人に1人しかいないらしい。この言い回しを算数の教科書に導入した人は責任を取るべき。
タグ:
posted at 16:10:03

@hijiridesign いいぞ ベイべー!
この問題ができないのは普通の小学生だ。できるのは
#超算数 をよく訓練された小学生だ。
ホント 算数は地獄だぜ! フゥハハハーハァー
タグ: 超算数
posted at 16:28:25
新しい記事がQiitaにアップされました!#Julia言語 #Julia日本語記事
qiita.com/StrawBerryMoon...👈
タグ: Julia日本語記事 Julia言語
posted at 16:45:18

#超算数 【どんな数をもとにすると】に関連して、日本文教出版の算数教科書twitter.com/genkuroki/stat...と東京書籍twitter.com/genkuroki/stat...の比較がなされた。6社の中で東京書籍方式がどれほど一般的かは未調査。ただし、現行指導要領の文科省による解説(2017:44)での用語は【数のまとまり】。ALT みてね。 pic.twitter.com/Km0PcDUzma
タグ: 超算数
posted at 16:58:11
#超算数 上のツイで画像に500字越えのALTをつけようとしたのだが、弾かれたようだ。文科省謹製の指導要領解説算数編のURLを3つつけようとしたのだ。
現行のもの
www.mext.go.jp/component/a_me...
前回のもの
www.mext.go.jp/component/a_me...
www.mext.go.jp/component/a_me...
タグ: 超算数
posted at 17:04:58
#超算数 さらに305ページには【第6学年においては,比べるために必要となる二つの数量の関係を,比例の関係を前提に,割合でみてよいかを判断する。そして,どちらか一方を基準にすることなく,簡単な整数の組としての二つの数量の関係に着目する。】とも。前回の指導要領解説にはない記述かも。 pic.twitter.com/63Xw7MU4B8
タグ: 超算数
posted at 17:23:08
@OokuboTact これだけ不十分な財政金融政策(我々は統合政府=中央政府+中央銀行で経済政策について考える)でこんなに失業者を減らして実質賃金も上昇させた、というのが私に感覚。
「掲示板」時代はこんなに「財政緊縮も金融引締もダメ!」と言う人が増えるとは予想できなかった。
どう見ても我々の勝利(笑)
タグ:
posted at 17:32:48
@OokuboTact 小島氏は、統計学の本でも評判が悪く、経済政策論争でもボロ負け。何をやってダメで、社会的に負の貢献をしまくっている。
誤りと勉強不足を認めることで社会貢献するといいと思うのだが、大久保さんの引用を見ると無理そう。
タグ:
posted at 17:36:46
@OokuboTact こういうのは本当に怖くて、ルサンチマンで心が暗黒に染まってしまうパターンを相当に目にして来た。
ゲラゲラ笑いながら自分のバカさを訂正して行く明るさがないと人生つらくなる。
タグ:
posted at 17:47:06

「小規模のRCTなら有意差が出ているものが多い」という事実は、どちらかというと、効果を疑わせるものだと私は考えます。出版バイアスの存在を示唆するからです。
タグ:
posted at 17:55:55
これ(P値函数→信頼区間)と同じことをパラメータ空間が2次元以上の場合にコンピュータで実装するのは結構面倒だが、ベイズ統計版を考えてMCMC法を使うことにして事後分布の様子を見ることで代用するならコードを書くのはずっと楽になる。
このベイズ統計の利点は実践的には無視できないと思う。 twitter.com/genkuroki/stat...
タグ:
posted at 18:02:12



OokuboTact 大久保中二病中年 @OokuboTact
「統計学と指導要領の解説」について調べていたら、算数教育の偉い人とも繋がりがありそうな気配が出てきた
#超算数
タグ: 超算数
posted at 19:44:35
新しい記事がQiitaにアップされました!#Julia言語 #Julia日本語記事
qiita.com/StrawBerryMoon...👈
タグ: Julia日本語記事 Julia言語
posted at 20:06:40

立憲民主党選任の、はたともこがヤバいのはHPVワクチン反対だけでない。
今や普通に定期接種化された、乳幼児のHib・肺炎球菌ワクチン定期接種化にも、国会議員で『唯一』反対票を投じた反ワクチンだから
立憲民主党は『乳幼児』の細菌性髄膜炎を軽視してるのかね?
www.jiji.com/sp/article?k=2...
タグ:
posted at 20:47:33

@temmusu_n 「スモールステップ」や「発達の段階説」の弊害の一例ですかね。
「易 割合→比の値→比 難」という「信念」を算数教育界wでは持っていそうですね。
タグ:
posted at 20:53:58
@takusansu #超算数 これには歴史的な用語があって、系統学習とか系統指導と呼べばいいはずです。中島健三氏が最初に担当した学習指導要領はそういう方針で編まれたとされていますwww.dainippon-tosho.co.jp/math_history/h...。
タグ: 超算数
posted at 21:34:50
@takusansu #超算数 積分定数さんがよく挙げる例だと、算数教育では二等辺三角形の定義として2つの角が等しいは不適切とみなされるんですよね。2辺が等しいが定義で、こっちは性質だとかいわれるそうで。同じようなループ、バックドア、エレベーター、落とし穴は算数にいっぱいあるはずですが、指導されないかも。
タグ: 超算数
posted at 21:41:48
@takusansu #超算数 カリキュラムは全国共通であるべきとか、ともかく1ページから250ページまで読み通すべき教科書を編集しなければいけないとかの拘束条件があるので、あまり融通性が持たせられないのかもしれませんが。
タグ: 超算数
posted at 21:46:27

Julia Computing Newsletter September 2021: Get everything you need to know about Julia including the latest news, updates and blogs from across the globe. juliacomputing.com/blog/2021/09/n...
#julialang #newsletter pic.twitter.com/D04Em3kBib
タグ: julialang newsletter
posted at 22:13:35


ぼく「将棋の盤と駒をお借りしたく……」
女将さん「“普通の”ならありますよ」
ぼく「お願いします」
~数分後~
ぼく「普通!?!?!?!?!?」 pic.twitter.com/0tH1Cr91jO
タグ:
posted at 22:42:47


New post: Deep Learning with Julia - www.juliabloggers.com/deep-learning-... #julialang pic.twitter.com/jpgO3hjZ0N
タグ: julialang
posted at 23:23:17
New post: Creating and Deploying your Julia Package Documentation - www.juliabloggers.com/creating-and-d... #julialang pic.twitter.com/GxzQ2I2kTI
タグ: julialang
posted at 23:23:23
New post: Developing your Julia package - www.juliabloggers.com/developing-you... #julialang pic.twitter.com/GJFeXdslo9
タグ: julialang
posted at 23:23:30
New post: Analyzing Graphs with Julia - www.juliabloggers.com/analyzing-grap... #julialang pic.twitter.com/6ItYzo6Ov6
タグ: julialang
posted at 23:23:37
New post: Installing Julia on Ubuntu - www.juliabloggers.com/installing-jul... #julialang pic.twitter.com/4uOZYVHSlC
タグ: julialang
posted at 23:23:57
New post: Speeding up Julia precompilation - www.juliabloggers.com/speeding-up-ju... #julialang pic.twitter.com/vfOksXJR6X
タグ: julialang
posted at 23:24:07
