
黒木玄 Gen Kuroki

- いいね数 389,756/311,170
- フォロー 995 フォロワー 14,556 ツイート 293,980
- 現在地 (^-^)/
- Web https://genkuroki.github.io/documents/
- 自己紹介 私については https://twilog.org/genkuroki と https://genkuroki.github.io と https://github.com/genkuroki と https://github.com/genkuroki/public を見て下さい。
2020年02月03日(月)

ごまふあざらし(GomahuAzaras @MathSorcerer
Documenter.jl を経由した導入方法を
qiita.com/SatoshiTerasak...
に書きました.あえてJuliaのパッケージの文脈を外したアプローチで書いていますが,パッケージに付随するドキュメントの書き方の参考にもできるようになっています.
ローカルで結果を確認したい場合は Julia と Python3.7 が必要です twitter.com/MathSorcerer/s...
タグ:
posted at 00:02:54

エガちゃんのYou Tubeチャンネル
冒頭の発言が単なるお笑い芸人の美学を超えて
クリエイター達への箴言にも聞こえて
心にグングン来た pic.twitter.com/6Anj4JlPcp
タグ:
posted at 00:46:50


yasunoxx▼Julia/h+JP @noisequeen
@bedroombeatmake atanとかsqrtとかねw
一度フォームを整えておけばexcelは便利よね。うちは微積分まではexcelでやってるw
定型の計算はJulia言語に移行しようとしてる所。
タグ:
posted at 02:09:42


@toshizumi1225 なるほど。そして仮説が正しい確率に行き着く、と。個人的な感想としては、統計学の不適切な使われ方を防ぐ統計的な方法というのは土台無理な話と感じますし、筋違いな要求のようにも聞こえます。研究実践の問題を統計だけが背負わされているようにも思います。
タグ:
posted at 02:14:12

@stattan @toshizumi1225 非常に単純な話で、豊田秀樹さんに代表される「ベイズ統計なら仮説が正しい確率が計算できる」とか言っている人たちは、その発言によって将来さらに別の悪質なquestionable research practicesが増える可能性を増やしているわけ。
この話題では豊田秀樹さん的考え方の否定は当然。 #統計
タグ: 統計
posted at 02:56:23
@stattan @toshizumi1225 あと「仮説が正しい確率」がらみの話題に有意義に参加したければ以下のリンク先に書いてあるような高校もしくは学部レベルの話題について来れないと苦しいです。
ベルヌイ分布モデルによるサイズnのサンプルを用いた推定はnに対する二項分布モデルによる推定と同じである程度のことは常識的。 twitter.com/genkuroki/stat...
タグ:
posted at 03:02:56
@stattan @toshizumi1225 #統計
www.cscd.osaka-u.ac.jp/user/rosaldo/1...
好ましくない研究行為(QRP)
を問題にするなら、
sites.google.com/site/kokiikeda...
から読める
池田功毅・平石界 (2016) 心理学における再現可能危機: 問題の構造と解決策. 心理学評論, 59 (1)
とその「追加的ノート」(論文より長い😅)の方を参照するべきだと思います。
タグ: 統計
posted at 03:10:21
@stattan @toshizumi1225 #統計 仮に論外である「ベイズ統計なら研究仮説が正しい確率が分かる」というようなクズのような考え方を排除して、真っ当なベイズ統計の使い方を普及させたとしても、ベイズ統計を用いたずるを防ぐような制度設計が必要な可能性が高いと思います。
ここでも「頻度論vs.ベイズ」という見方は無意味。
タグ: 統計
posted at 03:14:14

「一目置かれるような人間であれば、まともな欧米人はアジア人だからと差別するようなこともない」
“一目置かれるような人間であれば差別しない欧米人”が「まともな」人間か。🤣 twitter.com/hakkuriu/statu...
タグ:
posted at 03:18:19
@stattan @toshizumi1225 #統計 「理解してなくても結構使えること」は統計学のコンピューターソフトウェアによる実装の普及ですでにかなり実現されています。
しかし、「安全に正しく」使うことの実現は、池田さん達が述べているように、「ずるをした側が有利な状況」を放置したままでは無理。統計学側の問題ではない。 twitter.com/toshizumi1225/...
タグ: 統計
posted at 03:23:33

 非公開
非公開
タグ:
posted at xx:xx:xx
@toshizumi1225 @abiko_ushi 以下のリンク先を見る限り、まだ何も理解していないです。高校レベルの話題を理解できていない段階でもっと高給な話題に踏み込むのは意味がないです。以下は高校レベルの解説。
確率pで表が出るコイントスをn回繰り返したときに出た表と裏の列はベルヌイ分布のサイズnのサンプルです。続く twitter.com/toshizumi1225/...
タグ:
posted at 03:46:14
@toshizumi1225 @abiko_ushi #統計 続き。そのときに、n回中表がk回出る確率は
n!/(k!(n-k)!) pᵏ(1-p)ⁿ⁻ᵏ
になります(練習問題: 証明せよ)。これはちょうど二項分布の確率です。
n回中k回のkという1つの数値だけで、ベルヌイ分布のサイズnのサンプルの特徴(十分統計量)が記述され、それは二項分布で扱えるということです。
タグ: 統計
posted at 03:49:51
@toshizumi1225 @abiko_ushi #統計 nに対する二項分布モデルを使ったサイズ1のサンプルkによる推定は、ベルヌイ分布モデルを使ったサイズnのサンプルによる推定と自明に等価なのです。
二項分布は高校数学の範囲内なので、そこから勉強し直せば、サイズn=10のサンプルでの推定になっていることがすぐに分かると思います。
タグ: 統計
posted at 03:53:50
@toshizumi1225 @abiko_ushi #統計 相互リンク
ベルヌイ分布モデルを使ったサイズnのサンプルx_1,...,x_n (x_i は表または裏)よる検定や推定が、nに対する二項分布モデルによるサイズ1のサンプルk(=表の数)による検定や推定に等価なことは、統計学入門の教科書には必ず書いてあることです。
地道な勉強が大事。 twitter.com/genkuroki/stat...
タグ: 統計
posted at 04:02:03
#統計 資料
ああ、そうか、私も「特にひどい部分」としてその部分を引用すればよかった。
奥村晴彦さんはその本を読む前に渡辺澄夫『ベイズ統計の理論と方法』を参照済みのはずなのにどうしてこういうことになったのか?続く twitter.com/pubgbugreport/...
タグ: 統計
posted at 04:27:46

内申点が害悪な件、自分は内申点で損したことが全くないのだけど、神奈川県で塾のバイトをしていたときに、あまりにも公立高校の内申点の比重が高くて、テストはできるのに内申点が低くて受験を諦めている子がいて大変そうだなと思ったことがある。
タグ:
posted at 04:28:40
ごまふあざらし(GomahuAzaras @MathSorcerer
CSS を作ってカウンターと定義するやん?
マークダウン上では
```@ raw html
<div class="theorem">
何かを書く
</div>
```
こっちに書いても良い.
というようなことをすると
あら不思議. pic.twitter.com/CxqcQftTlg
タグ:
posted at 04:38:35
ごまふあざらし(GomahuAzaras @MathSorcerer
CSS でカウンターを実現する方法は
qiita.com/HigashinoSola/...
が参考になりました.
タグ:
posted at 04:41:09

気になるツィートをたどっていったらここまで来た。長かった。でも大事な気がするので理解したくて、まずはリツィートする。 twitter.com/genkuroki/stat...
タグ:
posted at 04:52:19
ごまふあざらし(GomahuAzaras @MathSorcerer
#Julia言語
Documenter.jl のテストコードにある
github.com/JuliaDocs/Docu...
が有能だった.公式ドキュメントの方に記載されてない情報があって.ビビってる.
例えばmacroとして :bra を定義しておくとマークダウン中で
\bra とすることで newcommand 的なことをしてくれる.
便利じゃん!
タグ: Julia言語
posted at 04:53:46
#統計 小ネタ: 小サンプルでモデルのパラメータ数が多い場合の最尤法はオーバーフィッティングしてしまうのですが、ベイズ統計とは無関係に事前分布を考えてMAP法を使えば平均汎化誤差が下がる「非常にシンプルで計算し切ることが可能な例」として
nbviewer.jupyter.org/github/genkuro...
Stein推定
は有名。
タグ: 統計
posted at 04:59:22

New post: Stiff differential equations
www.johndcook.com/blog/2020/02/0... pic.twitter.com/p1wWzqxIwN
タグ:
posted at 05:26:56

Satoshi Ikeuchi 池内恵 @chutoislam
ちなみに某国でイランの翼賛勢力・政権が作っているテレビ局複数を視聴しているんですが、こういう時にガンガン広島・長崎の原爆映像流してアメリカの不当性を批判するので、「日本が反米の戦いの味方だ」とサブリミナルに刷り込まれて、現実の日本から離れた親日感情が維持される。 twitter.com/reuters_co_jp/...
タグ:
posted at 05:41:41
昔はコペンハーゲン解釈を馬鹿にしながら哲学的雰囲気も醸しつつ多世界解釈派だと名乗るのが賢い証しという雰囲気だったのだが、あの頃は(そして今でも)多世界解釈は完成すらしていないし、問題点だらけ。自分で定義すら語れない多世界解釈派は当時のポストモダン思想派とある意味近いものがあった。
タグ:
posted at 08:08:58
今ではコペンハーゲン解釈には観測問題がないことが分かっているし、標準的解釈だという位置づけが正しく確立しているわけだが、多世界解釈のほうは(これは宿命なののだが)トートロジー的な混迷の中を彷徨い続けている。
タグ:
posted at 08:12:58


確率空間が適当に作れないからこういう問いに答えるのはそもそも無理だと思っていたのだけれど,ベイズ統計学だとできるんですか? twitter.com/pubgbugreport/...
タグ:
posted at 09:18:39
@sanjutsu_yu 条件付き確率って言っても,事前確率が必要じゃないですか.ベイズの定理で確率を更新してゆくのはなんとなく分かっても,その出発点が分かりません
タグ:
posted at 09:27:59

@toshizumi1225 @stattan 【「頻度論とベイズの対立はすでに消滅している」と「ずるをした側が有利な状況を放置したままではいけない」という話はあの人もそうおっしゃっていたと記憶しています。】
あの人とは誰ですか?
そういう曖昧な言い方で「記憶」について述べられても困る。
第三者が確認できる情報を示しましょう。
タグ:
posted at 09:41:14
非公開
タグ:
posted at xx:xx:xx
非公開
タグ:
posted at xx:xx:xx
非公開
タグ:
posted at xx:xx:xx
#統計 奥村晴彦さんが書いていることは誤りで、ベイズ統計でも「仮説が正しい確率」は求まりません。
「正しい事前分布を前提にすれば求まる」という考え方でさえ、以下で説明する理由で無意味だと考えた方がよいです(すでに上で述べたことの繰り返し)。
続く
twitter.com/57tggx/status/...
タグ: 統計
posted at 11:14:50
#統計 平均予測誤差が小さい推定を行うためには、確率モデルp(x|w)と事前分布φ(w)をうまく取る必要があります。
確率モデルが不適切なら事前分布をどのように取っても推定は失敗します。
確率モデルが適切であっても、事前分布の取り方によって平均予測誤差が大きく変化することがあります。↓ twitter.com/genkuroki/stat...
タグ: 統計
posted at 11:20:45
#統計 奥村晴彦『Rで楽しむベイズ統計入門』では、予測分布を二項分布モデルの場合で説明して終わりにしています(p.63)。
しかし、二項分布モデルの予測分布は特殊で、ベイズ統計の多くの予測分布が持つ「推定できなさ具合が予測分布に出る」という性質が見えません。この点でも読者は注意が必要。 twitter.com/genkuroki/stat...
タグ: 統計
posted at 11:35:42
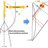
#統計 スクショは「Dice A,B,Cのどれかである」というモデルによる Dice Xの分布の推定の様子のプロット。
予測分布がDice AとCの平均に近くなっている。ベイズ推定さんは「AなのかCなのか分からん」と言っているわけです。
実際にはA,B,Cのどれからも遠い分布なので推定に失敗する。 twitter.com/genkuroki/stat... pic.twitter.com/lBZMALIKoO
タグ: 統計
posted at 11:56:48
#統計 いずれにせよ、ベイズ統計の予測分布の解説で、推定に失敗した場合の予測分布のプロット__も__大喜びで紹介しているような解説を読んだ方が楽しいし、ベイズ統計に関するより正しいイメージを持つことができると思います。
twitter.com/genkuroki/stat...
タグ: 統計
posted at 12:13:08
#統計 添付画像は
須山敦志『ベイズ推論による機械学習入門』
github.com/sammy-suyama/B...
より。私はこの本が好きです。機械学習やベイズ統計で飯を食うつもりがない人もこの本は楽しめると思います。M=10の予測分布は、M=10のモデルが「わからん!」と言っていることを示しています。 pic.twitter.com/Ka3iCXtaYV
タグ: 統計
posted at 12:24:22

2013年のScratch 2.0のリリース直前、レズニック教授が来日し、公立小のクラブ活動で1.4を使っている子供たちに2.0を紹介する機会がありました。新機能のクローンを知った子が何をしたかというと、再帰的にスプライトを増殖させることでした。結果、仕様にクローンの上限数が入ることになりました。 twitter.com/esumii/status/...
タグ:
posted at 12:28:29
クローンに限らず、Scratchは再帰を書ける言語ですが、普通にブロック定義(他の言語の関数定義に近い)して再帰するとスタックをどんどん消費します(末尾再帰の最適化を行っていない)。これを同期を取らない(「送って待つ」しない)メッセージで書くと、メモリの消費量は増えません。
タグ:
posted at 13:03:14

割りと前から気になってるんですが、EDAとHARKingの境目ってどうなってるんだろ?
EDAはデータ集めてとりあえずいろいろモデル作って仮説を探索してますが、HARKingも先にモデル作ってそこからわかることを仮説にしてますよね?
EDAとして行ったと素直に報告しないのがHARKingのだめなところ?
タグ:
posted at 13:33:47

驚いたとき何と言う?
私は「ひえー!ひょえー!」両方使っているかも。個人的な仮説で数学好き(数学の先生も)はオノマトペ多用しがち説を提唱している。
羽生善治九段も「ひえー」と叫ぶし将棋界ではみんな「ひえー」と声にして驚くけれど、それはいつからか?(松本博文) news.yahoo.co.jp/byline/matsumo...
タグ:
posted at 13:47:32

須山敦志 Suyama Atsushi @sammy_suyama
添付画像中の修正点
実践→実線 twitter.com/genkuroki/stat...
タグ:
posted at 13:50:43
須山敦志 Suyama Atsushi @sammy_suyama
校正に数百時間費やしていますがミスは消えないですね。致命的なものはまだ見つかっていませんが。
タグ:
posted at 13:54:30
EDAは検定しないし、モデルの探索(現代的な指標は使わない?)を先に宣言してる気がします。HARKingは目的を結果に合わせて変えて、さもそれが初めから目的だったかのようにする行為だと思います。 twitter.com/389jan/status/...
タグ:
posted at 14:02:23

切迫早産妊婦にたいするリトドリンの48時間投与(ショートトコライシス)と早産予防ペッサリーの使用についての読売の紹介記事です.ほとんどの切迫早産妊婦には長期入院,安静臥床管理は不要です.多くのひとに知っていただければと願っています. pic.twitter.com/fD5ItRg67N
タグ:
posted at 14:06:09
仮説を考える前にとりあえずいろいろモデルを作るのは同じだが、その手続きを公開するのがEDA、事後諸葛亮するのがHARKingですかね
twitter.com/stattan/status...
タグ:
posted at 14:06:16
「信念」を正しいベイズの定理(という名の条件付確率の)計算で更新してもそこで使ってるモデルは固定のままなのでいくらデータを与えてもモデルが表現できる範囲にとどまるんですよね。すぐ気づくことだからいいんでしょうか、というのが疑問。同時分布モデルの適切さがそもそも知りたいことなのに。
タグ:
posted at 14:49:55

ヘマトキリシン・エオジン染色をモチーフとした現代アートと呼んだ方がしっくりくる。この結論を捏造しようと企図する場合、電子データでなく撮影時からやってしまえば簡単なわけで、そうしなかったということはよっぽど実験してない(とりあえずの未発表検体すら手元にない)ってことなんだよな。 twitter.com/MicrobiomDiges...
タグ:
posted at 14:59:53
#統計 全然気付かなかった!
私は「数学的な事柄をよくわかっている人はどうでもよい所で気が抜けてつまらないミスをする」という仮説を信じています。😊
ツイッターを見ていると、みんなつまらないミスを連発していて仲間意識を持つことが多い。
twitter.com/sammy_suyama/s...
タグ: 統計
posted at 15:09:54

このレベルの改ざんが発覚しても、図の訂正を許容する出版社があり、研究機関はその訂正公告をもって一件落着とするというとんでもない話は日本だけではないので困ったことです。PubPeerのアドオンを入れておくと指摘がある論文には気付くことができます。 twitter.com/sugikota/statu...
タグ:
posted at 15:11:18
このときの記事が残っていました。こちらでは現在も毎月活動しています。 中原小応援団/中原はちのすけクラブ 2013年01月 hachinosukefan.blog33.fc2.com/blog-date-2013...
タグ:
posted at 15:12:41
須山敦志 Suyama Atsushi @sammy_suyama
僕も統計学の教科書を読んだ経験がほぼないので,ある意味統計初心者です.説明変数って言葉すら最近知りました.読む際は「内容を疑う」「"主義"で胡麻化さない」「自分で手計算・実装してみる」「手法→応用先を想像する」「課題→使える方法を考える」「拡張を考える」あたりが重要だと思います.
タグ:
posted at 15:41:51
須山敦志 Suyama Atsushi @sammy_suyama
あと多重共線性という言葉もごく最近知りました.そういうものにわざわざ名称がついている事実に感激しました.
タグ:
posted at 15:43:41
須山敦志 Suyama Atsushi @sammy_suyama
「統計入門」的な本を大学時代に1,2冊読んだ記憶がありますが,まったく血肉になっていないことから察するとやはり統計は数学的な理論を除いて座学だけで完結するのは難しいと思います.当時はKaggleみたいなコンペもまだ流行ってなかったですし.
タグ:
posted at 15:50:59
須山敦志 Suyama Atsushi @sammy_suyama
「手法には仮定・前提がある」「手法には適用範囲が存在する」「前提がうやむやな結論は疑う」「しきたりやチートシートは信用しない」あたりも重要
タグ:
posted at 15:58:51
須山敦志 Suyama Atsushi @sammy_suyama
あと個人的にはsklearnとかの↓こういうチートシートはあまり好きじゃないです.データ自体を理解し・価値を出そうとする姿勢に欠けていると感じます.
scikit-learn.org/stable/tutoria... pic.twitter.com/LCOSe7amrk
タグ:
posted at 16:02:36
#統計 確率モデルが積分で書かれている「階層モデル」に関する補足
「階層モデル」の予測分布の確率密度函数を直接求めようとすると、数値積分が大量に必要になりますが、事後分布のサンプルが得られているなら、予測分布のサンプルも軽めの計算で得られます。 twitter.com/genkuroki/stat...
タグ: 統計
posted at 16:09:20

“I’ve found that Julia is about 50-100x faster than other systems I’ve used that have similar flexibility – such as other dynamically typed programming languages and SQL databases.”
-Kevin Atteson, Atteson Research
juliacomputing.com/case-studies/a...
#julialang #financialmodeling
タグ: financialmodeling julialang
posted at 16:24:14


@elonmusk In the future you could consider Julia, gives python style rapid prototyping with C++ style performance. No second rewrite step needed. Has great machine learning libraries and easily runs on GPUs and other specialized hardware #JuliaLang towardsdatascience.com/complex-logic-...
タグ: JuliaLang
posted at 16:31:14

Japan e-Portfolioのロゴマーク、株式会社ベネッセコーポレーションが商標登録をしている。
それでいいのか?#一般社団法人教育情報管理機構
#大学入試改革
#ポートフォリオ pic.twitter.com/3HjOuCrPMb
タグ: ポートフォリオ 一般社団法人教育情報管理機構 大学入試改革
posted at 17:46:05

「宇崎ちゃんは遊びたい!」公式 @uzakichan_asobi
「宇崎ちゃんは遊びたい!」TVアニメ化決定ッスよー!!
2020年7月から放送が始まるみたいッス!!!!
公式サイトも本日からOPENしました!
uzakichan.com
#宇崎ちゃん pic.twitter.com/J2f7b2KmSJ
タグ: 宇崎ちゃん
posted at 18:03:00



非公開
タグ:
posted at xx:xx:xx


部活やらねば教員失格って意識もった人が相当数いる。部活は縮小すべきって言ったら、管理職に「なんで中学教員なったの?」って言われた事ある。「教科を教えたいから」と言ったら呆れ顔された。いつも「学びを大切に〜」とか言ったるくせにね。こっちが呆れましたよ。 twitter.com/Stop1clubsblac...
タグ:
posted at 20:15:32

A Beginner's Look at BenchmarkTools.jl
#Julia言語
www.juliabloggers.com/a-beginners-lo... @juliabloggersさんから
タグ: Julia言語
posted at 21:41:33

この件、「掲載誌に反対意見を投稿すると、自分の利益相反を開示しないといけない」と指摘された先生がいらして、なるほど、自分の資金源を隠して、相手の資金源だけを言い立てるために、議論の土俵に立とうとしなかったのかと思い当たった。 twitter.com/ymori117/statu...
タグ:
posted at 21:46:01
#統計 リンク先ツイート補足
私が「偽陽性の問題」と呼んでいたのは添付画像にある問題。添付画像は
bellcurve.jp/statistics/cou...
より。ベイズの定理を式で書いて、その式に数値を代入して計算しても、問題の状況で何が起こっているかについて理解が進むわけではない。続く twitter.com/genkuroki/stat... pic.twitter.com/sF6wHVkfjV
タグ: 統計
posted at 21:49:01
原文をお読みいただいた方はわかると思うけど、件の団体、以前から、気に入らない意見を封殺するために、相手の利益相反を針小棒大に言い立てる手法を良く使っていると指摘されている。 ja.ma/2UkTIyU
タグ:
posted at 21:50:07
#統計 続き。添付画像は
bellcurve.jp/statistics/cou...
より。このケースでベイズの定理を使う必然性はない。私は不要だと思っているベイズの定理をわざわざ覚えたい奇特な人だけがこのような問題の解き方をすればよい。
さらにこのケースでのベイズの定理の使用はベイズ統計とは何も関係__ない__。 pic.twitter.com/34W5b40GXk
タグ: 統計
posted at 21:52:50
#統計 続き。添付画像は
bellcurve.jp/statistics/cou...
より。このような「偽陽性の問題へのベイズの定理」の応用の解説があたかのベイズ統計の解説であるかのように、ベイズ統計に関する一般向け入門書に書いてあることが多いのだが、このケースでのベイズの定理の使用はベイズ統計の話になっていない。 pic.twitter.com/F0xc0fLvix
タグ: 統計
posted at 21:55:19
最初のツイート、現在700台のRTとfavをいただいている。関心を寄せてくださった皆様に感謝申し上げる。一方で、これがたとえば論文の妥当性の議論だったら、おそらくRTとfavは一桁だったろうとも思う。やはり、お金の話は分かりやすいし耳目をひく。件の団体が論敵の利益相反を誇張する所以だろう。
タグ:
posted at 21:55:46
正しいことは正しく主張する必要がある。自分と違う意見を持つ者の利益相反だけを強調し、印象操作に狂奔するより、まずは、ちゃんと学問をすべきだと思うのですよ。 twitter.com/ymori117/statu...
タグ:
posted at 21:59:24

#統計
bellcurve.jp/statistics/cou...
に書いてあること自体は正しいが、既知の確率分布における条件付き確率を正確に計算するだけに問題を扱っているに過ぎず、未知の確率分布の推定を行うベイズ統計の話とは何も関係がない。
これもベイズ統計だと教わって信じた人は騙されている。 pic.twitter.com/xuguhPBQke
タグ: 統計
posted at 22:02:01
#統計 このツイートを含むこのスレッドのすぐ上の部分に書いたように、未知の確率分布を推定するために使われるベイズ統計だけではなく、既知の確率分布における条件付き確率を計算する練習問題でもベイズの定理は使えます。
ベイズの定理を使ってもベイズ統計を基礎付けることは不可能です。 twitter.com/todesking/stat...
タグ: 統計
posted at 22:07:42
ごまふあざらし(GomahuAzaras @MathSorcerer
@691_7758337633 なるほど.私は,記号を乱雑に並べるよりも日本語を書くべきかなという気持ちが強かったです.
タグ:
posted at 22:11:10
同意
「⇔」記号で式を沢山繋げて得な場合は非常に少ない。
ロジックが複雑な場合には「⇒」「⇐」の証明を別々に説明した方がよい。多くの場合に片方は自明。
実際、「⇔」でざらざら式を繋げる人はわかっていないことが多い。
>3番目の⇔はどうやって証明したの?
↓
>………(回答できない) twitter.com/691_7758337633...
タグ:
posted at 22:20:29

もしも「⇔」記号でざらざら式を繋げるより、「⇒」と「⇐」の証明を別々に書いたほうが証明が簡潔になることが多いという意味なら同意。 twitter.com/691_7758337633...
タグ:
posted at 22:23:38
ごまふあざらし(GomahuAzaras @MathSorcerer
これ,質問する側にも質問される側の立場に多く経験したので
めっちゃわかります. twitter.com/genkuroki/stat...
タグ:
posted at 22:23:41

完全に愚痴です。
いま5年生を担任しているのですが、6年に進級したら、主任は朝の始業前に「自主的な清掃活動」を子どもたちにさせたいらしい。しかし、こちらから「やって」と言うのではなく子どもたちに「自分たちがやります」と言わせたいらしい。その時点で私は意味が分からないのですが、→
タグ:
posted at 22:25:30
主任は、「今度の集会の時に、学年全体にそういう話をゆうき先生からしてくれない?」と言うのです。
…意味分かりません。自分が子どもにさせたいのならご自分でしてくださいよ。子どもにやらせたくもないことをなぜ私が話さねばならないのでしょうか?何で私がそんなことを?理解できません。愚痴。
タグ:
posted at 22:28:51

斉藤 淳 『アメリカの大学生が学んでいる @junsaito0529
お節介ながら、ジム・ロジャースを引用しながら日本の危機を訴える知人に諫言したら、ブロックされてそれっきりなどと言うことがこれまでにもあり。。。
タグ:
posted at 22:29:14
斉藤 淳 『アメリカの大学生が学んでいる @junsaito0529
池上彰を真に受けている人、ジム・ロジャースを真に受けている人、はそれぞれかわいそうだと思う。
タグ:
posted at 22:30:28
ちなみに、私は朝の始業前に子どもに活動させること自体が大反対です。「8時までに登校しよう」という約束なのに、その前の時間にオフィシャルの活動があったらダメでしょ。そういう理不尽を押し付けることが6年のリーダー性を育てるとでも思っているならちゃんちゃら可笑しいです。愚痴です。
タグ:
posted at 22:31:43
斉藤 淳 『アメリカの大学生が学んでいる @junsaito0529
池上彰氏が、ある大学のリベラル・アーツ講座を担当すると聞いたときには、一般教養教育の死を予感しましたね、真剣に。その大学の幹部は、教養教育の意味が全く分かっていないと思いますね。
タグ:
posted at 22:31:53

同値性の証明の多くは片方向きが自明であり、非自明な向きの証明であっても特別なトリックが必要な部分はほんのわずかである場合が多い。
そう簡単には思い付きそうがない特別なアイデアをどこでどう使ったかが分かるように証明を書いてもらうと非常にうれしい。
タグ:
posted at 22:36:18

須山敦志 Suyama Atsushi @sammy_suyama
図中の「ラベルデータがあれば分類、なければクラスタリング」も酷い。分析者はいったい何がやりたいのか。データをもらってとりあえず進捗・成果を出したフリだけしたい人にとってはうってつけのガイドです。
タグ:
posted at 22:45:32

鈴木さん、いまだにこれはさすがにだめなんじゃないですかね。被曝影響がないことと論理的に整合しませんよ。無症状者への甲状腺エコーが有害であることは今や世界の常識だと思います |
執刀医「甲状腺検査継続を」|NHK 福島県のニュース www3.nhk.or.jp/lnews/fukushim...
タグ:
posted at 22:52:23

野田隼人 Atty. NODA Haya @nodahayato
こういうのを見るたびに、オンラインの名誉毀損について弁護士が成功報酬制で受任する仕組みがあると楽しいのではないかと思わなくもない。名誉回復の効果があるから、報酬率100%でも成立しそうだし。 twitter.com/smith796000/st...
タグ:
posted at 22:52:55

Ninja DAO | CryptoNi @CryptoNlnjaNFT
ステレオタイプの提示はリベラルアーツから一番遠いですからね。 twitter.com/junsaito0529/s...
タグ:
posted at 22:58:17
野田隼人 Atty. NODA Haya @nodahayato
「取れた金全部持っていって良いから潰しといてくれ」って、名誉毀損類型では割と合理的だと思う。
タグ:
posted at 23:04:02
斉藤 淳 『アメリカの大学生が学んでいる @junsaito0529
学生が「池上彰仕草」をしたら、昔自分が教えていた大学であれば即退学になる不正行為なのよ。コピペレポート、ネタ元引用せず、独自の分析なし。彼を教壇に立たせているということは、その水準でしか教育してません、って自白しているようなものなのよ。ja.wikipedia.org/wiki/%E6%B1%A0...
タグ:
posted at 23:05:19

@junsaito0529 @miyaharar 池上彰
名城大学教授、東京工業大学特命教授、東京大学定量生命科学研究所客員教授、日本大学文理学部客員教授、立教大学客員教授、経済学部特任教授、愛知学院大学経済学部特任教授、元京都造形芸術大学客員教授
ja.wikipedia.org/wiki/%E6%B1%A0...
タグ:
posted at 23:10:47
#統計 ほんとその通りで、事前分布φ(w)を「信念」の度合いとみなして、ベイズの定理で更新しても、確率モデルp(x|w)の側で大外ししていると、その「信念」とやらも大外ししていることになる。
確率モデルp(x|w)も信念で選んでいるからそういうことは気にしないというなら筋は通っている(皮肉)。続く twitter.com/katzkagaya/sta...
タグ: 統計
posted at 23:12:54
#統計 リンク先は、未知の確率分布を持つサイコロXの出目のデータ(サンプル)から、「サイコロXはサイコロA,B,Cのどれかである」という確率モデルでベイズ推定を行う様子の動画。
実際にはサイコロXはA,B,Cのどれとも大きく異なるのだが、事後分布はサイコロAに収束している。続く twitter.com/genkuroki/stat... pic.twitter.com/AFsrNBNquT
タグ: 統計
posted at 23:18:26
#統計 続き。この場合の、事後分布を信念や確信の度合いと解釈すると、リンク先の動画のベイズ統計使用者は(注意: その人にはサイコロXの真の確率分布は見えていない)、「サイコロXはサイコロAである」と最終的に確信するようになってしまっている。
その確信は大外ししているのだが(笑)。 twitter.com/genkuroki/stat... pic.twitter.com/XY3yiYHnf9
タグ: 統計
posted at 23:22:35
#統計 続き。「サイコロXはサイコロAである」という「研究仮説」(笑)をリンク先に動画のベイズ統計使用者が事後分布(posterior)で測った確率で評価したとすると、その「研究仮説」(笑)が正しい確率は最終的にほぼ100%になる。
実際にはサイコロXとAは全然違うのだが。 twitter.com/genkuroki/stat... pic.twitter.com/JkIrz9SQ7P
タグ: 統計
posted at 23:26:09
#統計
以上で紹介したようなベイズ統計適用の簡単な例を知っていれば、「研究仮説が正しい確率」とか言われても、「こいつ、何を馬鹿なことを言っているのやら」(笑)と感じざるを得なくなるはず。
確率モデルが大外ししていると、その確率モデルの範囲でのあらゆる仮説は大外ししているのだ。 twitter.com/genkuroki/stat... pic.twitter.com/yF8aJ5uJix
タグ: 統計
posted at 23:29:58
#統計
しかも、確率モデルが大外ししていても、ベイズ統計が満たしてる一般的な数学的法則によって、サンプルサイズ→∞でベイズ更新は収束して、大外ししているある種の仮説が正しい確率の事後分布で測った値がほぼ100%になってしまうのだ。
以下のリンク先の動画では実際にそうなっている。 twitter.com/genkuroki/stat... pic.twitter.com/BnwytxmfBl
タグ: 統計
posted at 23:38:51

www3.nhk.or.jp/lnews/fukushim...
鈴木主任教授は、「これまで治療した症例に過剰診断がないとまでは言い切れないが、極めて限定的であり、甲状腺検査が有害であるとは言えない」と
問題はそこじゃなくて、厳密な意味での過剰診断が少なくても予後を改善しない子どもの手術が増えていれば有害
タグ:
posted at 23:55:01
#統計 このツイートを含む長大なスレッドを閲覧して頂ければ分かるように、私は数年前からほぼ同じ計算を(MATLABではなく) #Julia言語 でしています。
私がプロットした経験ではサンプルサイズ10万のモンテカルロシミュレーションで十分です。1万だと足りず、100万だと無駄に計算時間が増える。 twitter.com/koichi_5963/st...
posted at 23:58:52
