
黒木玄 Gen Kuroki

- いいね数 389,756/311,170
- フォロー 995 フォロワー 14,556 ツイート 293,980
- 現在地 (^-^)/
- Web https://genkuroki.github.io/documents/
- 自己紹介 私については https://twilog.org/genkuroki と https://genkuroki.github.io と https://github.com/genkuroki と https://github.com/genkuroki/public を見て下さい。
2020年10月28日(水)

juliaの公式( docs.julialang.org/en/v1/ )に "It is multi-paradigm, combining features of imperative, functional, and object-oriented programming. " とか書いてあるから、別にオブジェクト指向言語ではないと言うことはないと思う。 / “非オブジェクト指向言語Julia…” htn.to/391PVkhEEC
タグ:
posted at 00:12:15

Juliaはオブジェクト指向言語ではないことはないと。Mathematicaは、関数を重ねるだけで、オブジェクト指向言語となります。
別にJuliaにケンカを売っている訳ではなくて、Mathematicaを多くの人に知ってもらいたいと、つい、Juliaをダシに使ってしまいました。 twitter.com/enkinho/status...
タグ:
posted at 00:30:23


 非公開
非公開
タグ:
posted at xx:xx:xx
非公開
タグ:
posted at xx:xx:xx

pythonでいうところのcollections.Counterの
Julia版はStatsBase.countmapってことでいいのかな pic.twitter.com/2gPRGxzlKQ
タグ:
posted at 06:20:24

いい話だけど、最後の「博士の愛した数式 」からの引用は若干引っかかる。
【博士が私たちに求めるのは正解だけではなかった。何も答えられずに黙りこくってしまうより、苦し紛れに突拍子もない間違いを犯したときの方が、むしろ喜んだ。】
タグ:
posted at 07:17:58
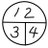
Bは3と5から、5-3とでもしてテキトーに出したのだろう。x=2を代入すれば3x=5が成り立つと本当に思っていたなら、それはそれでまずい。どちらにしても、Bに評価する点はない。
タグ:
posted at 07:23:26
AとBでは、Aの方が理解度が高いと言える。Aもx=2を階の候補としたかもしれない。で、代入したら成り立たない。
A x=2は解ではない
B x=2が解
Aは正しく認識しているが、Bは間違った認識をしている。
タグ:
posted at 07:24:38
www.ki1tos.com/entry/2020/10/...
ここに書かれているような、試行錯誤の過程で結果的に誤りというのと、
何が正解なのか、出した答えが本当に正解なのか自分で確認可能な数学の問題は
同列には扱えない。
タグ:
posted at 07:26:10


#統計 パラメータwを持つ確率分布モデルp(y|w)のw=w₀の場合でデータが生成されていると都合良く仮定しているならば、確かにw=w₀はデータを生成した確率分布のパラメータになります。
しかし、これと最尤法を使っているかどうかは無関係だし、その都合の良い仮定自体も検討する必要があります。続く twitter.com/KMKTo/status/1...
タグ: 統計
posted at 10:34:06
#統計 モデルを正規分布以外に一般化したとしても、その一般化されたモデルの範囲内でデータの生成法則が正しく記述されているとするのは都合の良過ぎる仮定になります。
採用したどのモデルの中にも正解が含まれていない可能性があることを正直に説明していなければ非科学的な態度になります。 twitter.com/tbs_i/status/1...
タグ: 統計
posted at 11:55:15


Naturalclar(Jesse K. @natural_clar
Github の README とかでもある方法で CSS を使える事実を初めて知った。
GithubのProfileとかもCSS職人は色々遊ぶ事ができるんだな
github.com/sindresorhus/c...
タグ:
posted at 13:22:27


非公開
タグ:
posted at xx:xx:xx

非公開
タグ:
posted at xx:xx:xx
非公開
タグ:
posted at xx:xx:xx

#超算数
掛け算順序カルト anond.hatelabo.jp/20200604104633
順序固定じゃなくてそれに反対する側が「カルト」らしい。
>なんかの利権が絡んだ運動かと勘ぐるほどだ
利権運動なのかな?
順序反対は利権になるの?だとしたらラッキーw俺も利権にあやかりたいw
タグ: 超算数
posted at 16:11:06

> 究極的なスピード勝負でRustはC言語に勝てない
こんな事は全く無くて、もはや言語関係なく、特定のアーキテクチャ上での速度はCPUの気持ちが分かる人が最適化したかどうかだけでほぼ決まっている
タグ:
posted at 16:22:54
実行時に配列の境界チェックを行うかどうかについては非常に込み入った問題があるけども、多くの場合で Rust は Julia に比べて外せてる方だと思いますね...
タグ:
posted at 16:27:31

@kaitou_ryaku Rustは基本的に実行時に評価しないといけない Mutex などを除いて実行時でなくコンパイル時にチェックするように頑張るので、よく分かっている人が書くなら基本的に実行時にチェックが走らないように書くはずですね
タグ:
posted at 16:40:33
@bicycle1885 f(a) のような値を評価しようとしたときに、fのコードをaの情報を使って最適化しても大丈夫だと思っての発言なのですが、これは禁止されている(aに依存しないコードを生成するように決まっている)ということでしょうか?
タグ:
posted at 16:45:27

Rustは現状では抽象化レイヤが厚いせいでllvmのご機嫌をとりにくいのがつらい。Cだと探索空間を意図的に特定の方向に狭めることで意図した結果を生成させることができてこれが高速化の最後の一押しになるのが強いのだけど、なのでCが良いというのは正しい判断ではないというやつ、、
タグ:
posted at 16:45:53

Dr. Chris Rackauckas @ChrisRackauckas
We demonstrate that using the #julialang @SciML_Org tools, we can train physics-informed surrogates which accurately extrapolate to new physical regimes and predict turbulent vertical mixing in ocean dynamics. Our next goal is to take SciML to GCMs.
arxiv.org/abs/2010.12559 pic.twitter.com/olKIKmmxw7
タグ: julialang
posted at 16:49:09
広い探索空間で迷わないようにちゃんと勾配をつけられることが大事で、アノテーションがリッチなalt llvmが勾配がなさすぎる問題を緩和すると良いなと思っている、、、
タグ:
posted at 16:49:18
Cにおける高速化テクニックと呼ばれるやつ、しばしば探索空間を特定の方向に狭めるために言語仕様とかコンパイラの特性を悪用しているものがあって、本質が見えなくなっていることがある。とれる手段が限られているので仕様を元の意図から外れて使ってますというのをちゃんと明示して説明したい、、
タグ:
posted at 16:59:39


@genkuroki ご解説ありがとうございます。恐れ多いです。「データを生成する分布も、仮定によって使われているのだから、結局数学的モデルに過ぎないのでは?」という疑問で引っかかっていたので、だいぶスッキリです。ご指摘の通り、教科書では確率分布を適用することは実は割と強い仮定⬇️
タグ:
posted at 17:02:35
@genkuroki だと明示する事があまりない様な気がしています。「この条件だと二項分布である事が多い」等はよく見る記述ですが。
自分はベイズ推定を初めて勉強したのが「KeyのStatistical signal processing」で、この教科書では「ベイズ推定はパラメータにある種の拘束(事前分布)を与えたいときにベイズなのだ」
タグ:
posted at 17:06:57
@genkuroki というシンプルな動機で解説されており、かなり分かり易かったです。しばらく後に、巷に溢れるベイズ推定に関する説明を読み始め大変混乱しました。師の説明で、ここらへんのあやふやだった部分がスッキリして参りました。ありがとうございました!!
タグ:
posted at 17:09:42
@termoshtt そう言われると原理的にはJuliaが有利だと言えるのは確かだと思うのですが、現実的に配列のサイズに特化した最適化が適用できてかつ有効なことってそんなに多いかは疑問です。
タグ:
posted at 17:10:02

@termoshtt あと並列実行を考慮すると、Juliaみたいに所有権がないと、配列サイズなどが実行中に変わらないことをコンパイラが勝手に期待していいかと言うと微妙な気がします(data raceが発生してたらそもそも未定義ですが)。その点Rustの方が有利かも知れません。
タグ:
posted at 17:28:50

@genkuroki その区別は非常に大切ですよね。特に1の重要性と難しさは骨身に染みてわかります。ただ、データからどうモデル化するかを丁寧に解説した教科書をあまり見た事がありません。一般化が難しいのかもしれません。
物理モデルが背景にある場合はある程度簡単なのですが。。
タグ:
posted at 17:48:00

娘の宿題のルールに則して考えるなら、
「式が6×3になるほうを選びなさい」という問題があった。
「A. 6人に3本ずつ鉛筆を配るとき、鉛筆は何本必要か」
「B. 箱が3つあり、1箱に6個の消しゴムがあるとき、消しゴムは何個か」
タグ:
posted at 17:55:18
@SGThr7 #Julia言語 バックエンドの問題です。
Plots.jl のバックエンドとしてデフォルトのgr()は速くて便利なのですが、細部がちょっと雑。
pyplot()の方が安定している部分が多いという印象があります。
バックエンドの切り替えは現時点では結構重要。誰か手を出してきっちり仕上げれば良いのでしょうが。 twitter.com/genkuroki/stat...
タグ: Julia言語
posted at 18:00:00

@genkuroki windowsをつかってて、Juliaはジュピターで動くんですけど、pycallがどうしてもインストールできません。
この文章を読むに、Pythonは別口でインストールが必要なのでしょうか?
タグ:
posted at 18:02:55
@SGThr7 #Julia言語
nbviewer.jupyter.org/gist/genkuroki...
Plots.jl でのgr()とpyplot()での日本語フォントの使用の比較。
pyplot()の方を使うべき。 pic.twitter.com/REbfaE1QSQ
タグ: Julia言語
posted at 18:05:36
@EZX2FOFxVpvStIK 【Pythonは別口でインストールが必要なのでしょうか?】
いいえ。
別口でもインストール可能ですが、上の方法だとJuliaが~/.julia/conda/3以下にPythonさん御一行をインストールしてくれます。
nbviewer.jupyter.org/github/genkuro...
PyCall, PyPlot, SymPyをインストール
(1) PyCall.jl
を参照。 #Julia言語
タグ: Julia言語
posted at 18:09:42
@EZX2FOFxVpvStIK 理由は分かりませんが何か失敗しています。
失敗の様子(具体的に何をやったかのすべて、キー入力のすべて、表示されたエラーメッセージのすべて)の情報がないと、「何か失敗している」以上のことは言えないです。
タグ:
posted at 18:40:57
@genkuroki Julia前に一度公式からダウンロードしました。ダウンロードの方法は【1から始めるJuliaプログラミング】に習ったものです。
ダウンロード後、Juliaの標準のパッケージ管理ツールでpycallをインストールしました。インまストールは出きるのですが読み込もうとするとエラーがおきます
タグ:
posted at 18:46:46
@genkuroki エラー文は、pycall not properly installed. Please run Pkg.build(pycall)です
ここで一旦、Juliaを再インストールすることにしました。以前あったフォルダを消去して再インストールしてみました(いまここ)
タグ:
posted at 18:48:54

Juliaの型推論アルゴリズムを実装する|Shuhei Kadowaki zenn.dev/aviatesk/artic... これについて、各変数が取りうる抽象値CがLatticeでいいのかかねがね考えている。多分、Latticeじゃない別解がある気がする。flow sensitiveな解析をサポートするならなおさら
タグ:
posted at 18:56:21

function f3()
a = rand(2100)
end
@ btime f3()
function f4()
a = rand(100)
end
@ btime f4()
1.993 μs (2 allocations: 16.52 KiB)
157.628 ns (1 allocation: 896 bytes)
メモリアロケーションの発生がサイズによるらしい。#julialang
タグ: julialang
posted at 18:58:43

A Hubble Space Telescope color image of the core of the globular star cluster Omega Centauri is used to construct a Hertzsprung-Russell diagram of the stellar populations in the cluster buff.ly/2JtMkfR [what is an H-R diagram: buff.ly/2VMMbe9] pic.twitter.com/WltBv1y1kw
タグ:
posted at 19:01:08
例えば、flow sensitiveな解析で取りうる型を限定したことで⊥では無くなる場合とか考えられる。ある程度実用的な抽象解析処理系を考えるとこのような場合を当然対応できなければならない。そうすれば内部表現は⊥とは違う値で保持すべきである
タグ:
posted at 19:04:12

久々にJuliaをしていると
Statistics with Julia: Fundamentals for Data Science, Machine Learning and Artificial Intelligence. statisticswithjulia.org のドラフトに行き着いた.コードもある.今年Springerから出版予定らしい.
タグ:
posted at 19:08:00


The misuse of colour in science communication www.nature.com/articles/s4146...
"We highlight ways for the scientific community to identify and prevent the misuse of colour in science, and call for a proactive step away from colour misuse among the community, publishers, and the press" pic.twitter.com/WNWDoOAsNz
タグ:
posted at 19:49:24
@EZX2FOFxVpvStIK nbviewer.jupyter.org/github/genkuro...
をよく読めば分かります。 pic.twitter.com/xc1uOOpqaR
タグ:
posted at 19:53:23




OokuboTact 大久保中二病中年 @OokuboTact
@sekibunnteisuu 掛け順を観測して10年くらいですが、年々ひどくなっているような気がします。
ワクチンを早く開発しないと手遅れに
タグ:
posted at 20:36:24
非公開
タグ:
posted at xx:xx:xx
OokuboTact 大久保中二病中年 @OokuboTact
@sekibunnteisuu でも「指導要領」と「指導要領・解説」の区別がつかない人ばかりなんで・・・
「文科省の指示でやってます、指導要領に書いてます」という勘違いする人がこれからも増えると思うと、頭が痛いです。
タグ:
posted at 20:40:22

その文献→
個体レベル:
Kagaya, Patek 2016
jeb.biologists.org/content/219/3/...
Harada+2020
peerj.com/articles/9036/
Wakita+2020
doi.org/10.1098/rsif.2...
細胞レベル:
Kagaya+2020
doi.org/10.26508/lsa.2...
です。下2つでGLMのほうが良くなりました。積分計算しない場合は逆になりました。
タグ:
posted at 20:41:45
OokuboTact 大久保中二病中年 @OokuboTact
@sekibunnteisuu 算数教育の専門家でも、「指導要領」と「指導要領・解説」を区別していても、法的強制力の違いを無視して同列に扱って、自説の根拠として引用するのが常識になっているので、ヤバいです。
タグ:
posted at 20:42:02
いずれにしても「個体差や場所差など考慮する方が良い」とあった時に「そこの良いはどういう意味の良いなのか」という疑問をずっと持ってきたのですがシンプルなモデルではありますが査読者の説得と自分の納得が一応できました。
タグ:
posted at 20:58:28

jetとかrainbowとかのカラーマップはCIEDE2000色差の変化が一定でないし色弱の方に配慮できてないので使わないようにと言う話 twitter.com/dsquintana/sta...
タグ:
posted at 21:06:46
@EZX2FOFxVpvStIK InitializeSecurityContext云々と怒られているので、セキュリティ関係の設定を確認すればよいのかも。
それでもダメならAnaconda3を入れてそちらを使うようにする。(そのための方法も既出の解説文にある)
Pythonとの連携ではまる人が多い。Juliaで閉じていることでは驚くほどトラブルが少ない。
タグ:
posted at 21:35:53

@EZX2FOFxVpvStIK #Julia言語 Windows curl.exe
表示されたエラーメッセージでググってみました。
例
↓
www.google.com/search?q=schan...
↓
discourse.julialang.org/t/problem-with...
↓
discourse.julialang.org/t/problem-with...
タグ: Julia言語
posted at 22:36:01
#統計 最近ツイッターで見せた例
Juliaでは最小二乗法の計算は b = X\y の1行で可能。
次数が11と高いせいでオーバーフィッティングしまくっている。 twitter.com/genkuroki/stat... pic.twitter.com/KpViN1GUvZ
タグ: 統計
posted at 23:16:53


ごまふあざらし(GomahuAzaras @MathSorcerer
自作 JLL を作るたびにビルダーとjll用のリポジトリとそれを使うためのパッケージのリポジトリが増える
#Julia言語
タグ: Julia言語
posted at 23:57:57
