
黒木玄 Gen Kuroki

- いいね数 389,756/311,170
- フォロー 995 フォロワー 14,556 ツイート 293,980
- 現在地 (^-^)/
- Web https://genkuroki.github.io/documents/
- 自己紹介 私については https://twilog.org/genkuroki と https://genkuroki.github.io と https://github.com/genkuroki と https://github.com/genkuroki/public を見て下さい。
2019年11月28日(木)

少し前の本ですが、AI、ビッグデータが差別を固定化することなどの問題を記した書籍として、「監視大国アメリカ」は、秀逸です。
関心がある方は、どうぞ。
www.harashobo.co.jp/smp/book/b3693...
タグ:
posted at 00:01:02

 非公開
非公開
タグ:
posted at xx:xx:xx

高河ゆん先生が「あまりにも生活がGoogleに支配されすぎて、Googleにすっかり染まってしまったから。」「日本製のクラウドサービスもあれば使ってみたいんだけど、あんまり人が使ってないサービス使っても仕方ないし」japanese.engadget.com/2019/11/25/ipa...
おまいら、頑張らないと。
タグ:
posted at 00:39:49

哲学者は哲学の話をしていて物理の話も数学の話もしていないから当然哲学者の話に物理の知識は必要なく、そもそも何一つ関係ない。たまたま同じ言葉を部分的に同じ意味で使いうるだけ、事情をきちんと明示した方がいいし、編集者は仕事をしてほしい。もはや哲学者というより出版社・編集者の仕事だろう
タグ:
posted at 00:45:19

#Julia言語
コツコツ貯めてたPGFPlotsXのexample集がいい感じになってきたので,Julialangでplotライブラリに迷っている人はぜひ参考にしてください.
gist.github.com/nobuta05/edc28...
タグ: Julia言語
posted at 00:51:16

#統計 自分で書いた函数と #R言語 の fisher.test や exact2x2::fisher.exact(A, midp=TRUE) と比較して、同じ値になることを確認し、単にサンプル以下になる確率を足し上げたP値(Fisher's exact test)と片側検定のP値の2倍をP値としたものを比較してみました。まず、P値の比較: pic.twitter.com/EiphfEPjYD
posted at 01:44:04
#統計 帰無仮説を満たすサンプルの分布のもとで、P値がα以下になる確率の比較。
P値がα以下になる確率は片側検定のP値を2倍にする流儀の方が小さくなります。
exact test と言えるためには、45度線に下から接する必要があると思うのですが、片側検定のP値を2倍する流儀ではその性質も失われます。 pic.twitter.com/DIbjbgK7s8
タグ: 統計
posted at 01:48:11
#統計
#R言語 の fisher.test が表示する信頼区間は「片側検定のP値を2倍する流儀」と整合的な信頼区間になっていることも確認できました。(私が書いたその流儀を実装した函数が表示する信頼区間と一致した。)
fisher.testが表示するP値は「サンプル以下の確率の和」です。
twitter.com/genkuroki/stat...
posted at 01:53:27
#統計
#R言語 のfisher.test函数のP値と信頼区間のあいだには整合性がないので、exact2x2::fisher.exactの方がおすすめ。
以上の実験で使ったソースコード(#Julia言語)は
nbviewer.jupyter.org/gist/genkuroki...
χ²検定とG検定とFisher検定の比較
でよめます。
posted at 01:56:34
非公開
タグ:
posted at xx:xx:xx
#統計 ちなみに、Yates補正のYatesさんの1984年の論文では「片側検定のP値を2倍する流儀」を勧めている。以下のリンク先の添付画像の項目6を参照。
私が思うに、Yates補正のYatesさんは色々間違った考え方をしていた。信用しない方が良さそう。
twitter.com/genkuroki/stat...
タグ: 統計
posted at 02:39:06
ちょっと気になる記事。
Googleが検索結果ページでクリックしないを繰り返すと検索結果を返さなくなるという。この筆者の方は全盲でテキストブラウザのLynxでGoogleが使えなくなったと悲鳴を挙げている。
# Gに伝われば直ると思うが... twitter.com/lobsters/statu...
タグ:
posted at 02:41:14

断言できるけど野口旭は金融政策と金融調節がわかってないと言ったバカにマクロ経済を語る資格は一切ない。というか頭悪すぎて賢そうな顔だけしてるのにいつも爆笑しかない。
タグ:
posted at 02:42:02

@ayuppppponyo1 @genkuroki 両方とも正解で問題ありません。が、数学的にも教育学的にも特に根拠のないルールに従わせることにこだわっておられる先生方が一定数いる状況です…
タグ:
posted at 03:17:06

"The DSGE community has picked up on new language Julia, with the Federal Reserve of New York alongside consultancy Liberty Street Economics updating its MATLAB DSGE model"
The Non-Contradiction of Proprietary Finance and Community Open Source Programming www.finextra.com/blogposting/18...
タグ:
posted at 04:53:27
世間の皆さまに、基礎物理学の面白さや人類全体にとってのその重要性を知って頂くために、アウトリーチの一環として、いろいろここでつぶいているのですが、それで本屋で、科学哲学の分野での時間とか量子とかのトンデモ哲学者の本に手を延ばされると、「そうじゃないです=!」と叫びたくなる。
タグ:
posted at 04:56:20
これは医学でも人文系でも起きていることだし、人それぞれのリテラシーに関わることなので、完全にトンデモに吸い寄せられることを無くすことはできないと思います。しかし最近で言うと、森田邦久氏が沢山書かれているような、物理学や数学を誤解しまくってる科学哲学本は絶対避けたほうが賢明です。
タグ:
posted at 05:03:17
特に日本の量子や時間の科学哲学本は、批判的視点を持ちながら読んで、著者の理解や知識の足りなさから来る、おかしな文章や主張や結論に出くわしたら、「ああ、またか」と笑い飛ばすくらいがちょうどいい現状です。
タグ:
posted at 05:07:41

Proud to have released my first Julia package!
Check out Python like FStrings.jl for Julia here:
github.com/magonser/FStri...
#julialang #FStrings #python pic.twitter.com/zzpR4YuoNF
posted at 05:08:41
娘「お母さん、寝る前のお話!」
母「『パラレルワールド』」
娘「ムー風は?」
母「『多世界は実在した!天才科学者が語る最新科学』」
娘「論文風に」
母「『現代量子力学における哲学的諸問題』」
娘「それがいい」
母「量子力学には深刻な観測問題がある」
娘「またか。わらうね。」
タグ:
posted at 05:13:59


例の質の悪い科学哲学者と物理屋の対談をまとめた書籍だけど、槍玉に上がっている他の2人の哲学者は置いておいて、青山拓央氏には自分の中でフェアな評価を書いておく。
タグ:
posted at 06:07:27
まず例え企画ものに乗せられたとは言え、哲学者と名乗るものは「対話」を軽んじるのはどうかという批判はしておく。しかしその学術的内容を書籍で見る限り、森田邦久氏のようないい加減な数学や物理の話を、敢えて避けているところは評価に値すると思っている。
タグ:
posted at 06:10:31
青山拓央氏の博士論文の時間と分岐の話などは、明らかに量子力学の解釈問題や古典力学も含めた時間反転対称性などの物理学の議論から大きな影響を受けているのは間違いないはずだ。しかし論の中には、敢えてだろうが、「量子」などのワードは含まれていない。
タグ:
posted at 06:12:52
大きな動機を物理屋の仕事からも得ながら、それに言及しない用心深い態度は、日本の哲学者としては珍しいほど、よほど自制心があるのだろうと感じた。この辺りは、森田邦久氏と大きく違う点である。
タグ:
posted at 06:14:40
谷村氏は多分に感情的な反論を書いたわけだが、それに青山氏は乗らず、注意深くしているにはどうしたらよいのかと考え、最善とは言えずとも、自分の身を守るより良い選択肢として、あの程度の駄目な哲学者の振る舞いで妥協しようと思ったのかもしれない。
タグ:
posted at 06:16:46
谷村氏は感情的になりすぎて、物理学至上主義や科学万能論の心情をぶつけたが、自由意思がないという主張に冷静な反論で返さず、「だって違うんだもん」で済ます人間達と谷村氏を青山氏は同じにみてしまったのかもしれない。
タグ:
posted at 06:19:12
理論物理屋だって、多くの場合は、現実の物理法則や実験結果を合わない設定を、思考実験としてよく考える。それでおかしなことが起きれば、現実世界が選択された理由が分かるかもしれないからだ。
タグ:
posted at 06:20:29
谷村氏だって、普段はそういう思考を喜び、評価しているはずだ。時間的閉曲線がある場合の量子計算の話とか。だから現実がどうあれ、心身二元論を考えることに最初から拒否をすることは、谷村氏も本来必要のないことのはずだ。
タグ:
posted at 06:22:47
日本の哲学業界は歴史的な負の資産もあり、いびつなままで、森田邦久氏が言っている変なことに対しても、学会内から特に厳しい批判が出たりしない、生ぬるい環境にあるのはきっと確かだろう。超心理学系の科学哲学者に対しても、そうだったように。
タグ:
posted at 06:25:10
そういう現状の哲学業界で、自分の身を守る策をとるのは、防衛本能として仕方がないが、それならば森田氏のような人達に利用されないよう、今後は気を付けるべきだ。また同時に、対話(ダイアローグ)も軽んじないようにすべきだ。そして、これは哲学業界全体の問題。
タグ:
posted at 06:27:14
今の現状を哲学分野の人達は、大いに恥ずべきだと思う。誰一人として、責任がないようには見えない。もっと学問としての哲学を愛し、喧々諤々と論じ合って、おかしいものはおかしいと、やりあって欲しいものだ。科学哲学者たちの変な尻ぬぐいを物理屋がやらざるを得ない現状を変えて欲しい。
タグ:
posted at 06:29:18

@jingbay @genkuroki この記事、2日前に twitter.com/EzoeRyou/statu... で気づきましたが、気づいた時点で確認したところ既に直ってました。今、再度確認しましたがやはり直ってますよ。
タグ:
posted at 06:41:52

ツイッターが非アクティブなアカウントを消すという話題、亡くなられた方のアカウントを記念にする仕組みが整うまで延期するとのこと twitter.com/twittersupport...
タグ:
posted at 06:48:22

数学の記述問題は,平成29年度の試行調査と平成30年度の試行調査とで大きく変化している。おそらく採点を簡単にする目的で答を単純にしたつもりだったのだろう。だから多様な別解の存在を予想もしていなかったと思う。
タグ:
posted at 08:01:05

Universal Curiosity @UniverCurious
Smartasses everywhere pic.twitter.com/pAKIF8WWj9
タグ:
posted at 08:29:46

「AI」屋さんが良くやる失敗ですが……
分析できます、と結論付けるのが早すぎるんですよね。
その分析が正確なのかどうかValidationあんまりやらない。
更に、Validationが終わってもいないものを実装したがる。
実世界への実装が与える影響の検討なんぞも全くしないんですよねえ… twitter.com/kahajime/statu...
タグ:
posted at 08:34:59
数値を放り込んでなにがしかの数値を出してくるのは簡単ですよ、そりゃ。
問題は「その数値にどんな意味があるのか」。そして「その数値を出すことで誰がどう動くのか」。
タグ:
posted at 08:38:34
実世界に向けて使うなら「これを使った結果」を考えなきゃいけない。倫理性の問題もあるからね。
少なくとも、「なんか結果が出たぜー使うぜー」程度のノリで出していいものかどうか、考える習慣は必要。発表するだけでも慎重にならなきゃいかんものっていくらもあるでしょ。
タグ:
posted at 08:41:31
#統計 ただし、exact2x2::fisher.exact(A, tsmethod="central")を使用するべきではありません。それだと、またしても「片側検定のP値の2倍」の流儀になってしまいます。その流儀では、P値が余計に大きくなり、Fisher's exact testの超幾何分布における正確性が失われます。
www.rdocumentation.org/packages/exact...
タグ: 統計
posted at 08:41:49
「分析の結果、〇〇と判りました」は間違い。
「この手法で分析した結果、〇〇という結果が得られました」だけでしかない。
結果が得られたことを公表する時に、この辺を発表者が混同してる事例もあるよね。発表する本人が混同してるんだから、読者にはもちろん違いは判らない。
タグ:
posted at 08:43:23
カギカッコつきで「AI」屋としてるのは、「検証する姿勢」が不足してるからです。中途半端なモデルかもしれない、近似できる範囲が狭いかもしれない、そういう『あって当たり前の懸念』すら持たずにキャワキャワとはしゃいでるだけだから。
タグ:
posted at 08:44:48
#統計 Fisher検定の「片側検定のP値の2倍」版と通常のFisher検定のP値がα以下になる確率を超幾何分布で計算してプロットしたのが添付画像です。
通常のFisher検定のグラフはその正確さによって45度線に下から接していますが、「片側検定のP値の2倍」版では接しなくなっています! pic.twitter.com/ypuQ9jPgLr
タグ: 統計
posted at 08:44:59

高三 和晃 / Kazuaki Taka @takasan_san_san
疎行列の扱いに不慣れすぎて、疎行列にしても全然早くならない。厳密対角化してるんだけど、Hamiltonianを一旦密行列で作ってしまって、対角化する直前で、sH=sparse(H), eigs(sH)みたいなことしてるんだけど、これだと無意味?
タグ:
posted at 08:47:22
@takasan_san_san 行列作成のところと対角化のところとどちらが時間かかってるか調べて、対角化のところがかわらないのでしたら、何かミスってますね
タグ:
posted at 08:49:21
#統計 要するに、Fisher検定の超幾何分布における正確性はその「片側検定のP値の2倍」版では失われます。
この「片側検定のP値の2倍」版はYatesさんが勧めており、非常に困ったことだと思います。
Yatesさんの1984年の論文の結論は色々ひどい。
mathfaculty.fullerton.edu/sbehseta/Yates... pic.twitter.com/cqhbxcQUfe
タグ: 統計
posted at 08:51:42
高三 和晃 / Kazuaki Taka @takasan_san_san
@cometscome_phys 確認してみたら
@time H=Hamiltonian(..parameters..)
@time eigen(H)
@time sH=sparse(Hamiltonian(..parameters..))
@time eigs(H)
ってしたら、
タグ:
posted at 08:58:59
高三 和晃 / Kazuaki Taka @takasan_san_san
@cometscome_phys @TIME どういうことが考えられるのでしょうか?疎行列にしたら早くなるのは、対角化するところだけですよね? 一応、ハミルトニアンの計算自体は、for文つかいまくりですが、全部関数化しているので、そこまで遅くはないはずです。1つ1つの関数にかかっている時間を測るのが正攻法なんだと思いますが。
タグ:
posted at 09:08:02
@takasan_san_san @TIME 0となる要素があらかじめわかっているなら、そこを0と計算しないように書くと短縮されます。たとえば行と列で、列のインデックスで回しながら、必要な少数の行インデックスだけをまわすとか。差分ならj+1とj-1だけ取ってくるとかですね。
タグ:
posted at 09:10:12
高三 和晃 / Kazuaki Taka @takasan_san_san
@cometscome_phys @TIME あ、一応いまはjuliaで書いてます!
タグ:
posted at 09:13:41
高三 和晃 / Kazuaki Taka @takasan_san_san
@cometscome_phys @TIME はい。。。まじでfor文使いまくりで、、、可読性高かったりして良いなってことでjuliaにトライしています。
タグ:
posted at 09:17:04
#統計 実践的には、2×2の分割表の独立性検定では、「基本的に補正無しのχ²検定を使うことにし、リンク先添付画像の左上隅のような偏りが生じることに注意を払う」ということでよいと思う。そして、その左上隅のような場合には、使用可能ならmid-P版Fisher検定を使う。
twitter.com/genkuroki/stat...
タグ: 統計
posted at 09:19:37
高三 和晃 / Kazuaki Taka @takasan_san_san
@cometscome_phys @TIME え、それで変わるんですか... 試してみます。
タグ:
posted at 09:25:19
#統計 Fisher検定のP値を表示するときには、mid-P版のP値も表示するべきです。両方のP値の値からちょっとした算数で理想的な棄却確率を計算できます。
シンプルで合理的で理論的にも整合的なスタイルを普及させることは大事。
twitter.com/genkuroki/stat...
タグ: 統計
posted at 09:28:07
高三 和晃 / Kazuaki Taka @takasan_san_san
@cometscome_phys なるほどです(c++多少書いてたのに何も意識せず生きてきた人)。
タグ:
posted at 09:28:24

#統計 大事なことなので再度強調。
「片側検定のP値の2倍をP値とする」版のFisher検定は超幾何分布下でも正確ではなくなっており、P値も余計に高めになる。ただでさえ低くなっているFisher検定の検出力をさらに下げてしまう。
使用してはいけない。
twitter.com/genkuroki/stat...
タグ: 統計
posted at 09:42:28
#統計 Fisher検定のP値がひどく高めになる理由は
(1) 縦横の合計を両方固定したことが原因で
(2) 有限離散性の問題をひどく悪化させているから
です。その様子は以下のリンク先以下の4つの添付動画を見れば直観的に把握できます。
twitter.com/genkuroki/stat...
タグ: 統計
posted at 09:48:47
#統計 以上は以下のリンク先のスレッドへのコメントのつもりでもある。反応があるのはとてもありがたいです。
独立性検定でのPearsonのχ²統計量の漸近挙動は、対数尤度比(G統計量)の漸近挙動と同じで、Wilksの定理から対数尤度比が漸近的にχ²分布に従うことが分かります。
twitter.com/bluesnono/stat...
タグ: 統計
posted at 10:06:02

そういや入試の採点をバイトにやらせると超算数の延長でsinθ+cosθが解になる問題に√2・sin(θ+π/4)と答えたらバツつけられるってことか。そう考えると三角比は変換で1つの数値を複数通りで表せるのをセンターは空所補充によってどの表現を採用するか明確化できると
タグ:
posted at 10:13:03

本当なら、今すぐ萩生田大臣が記述式問題の中止を決めたらいいのだ。なのに、無理を承知で突き進むのは、理屈にあわない。採点業者のベネッセを守ろうとしてるとしか思えない。50万人の子どもの人生を、ベネッセの儲けのために不公正な入試で台無しにするつもりか。絶対に止めなければならない。 twitter.com/urazumi/status...
タグ:
posted at 10:18:04
#統計 (1) 縦横の合計をすべて固定した条件付き確率分布において正確に確率を計算すると、リンク先のような強い有限離散的な結果が得られる。
条件付きでない確率分布での確率はこれらの足し上げ(重み付き平均)になる。
twitter.com/genkuroki/stat...
タグ: 統計
posted at 10:24:34
#統計 縦横の合計の固定を片方だけ解除するときの足し上げの様子の動画が以下のリンク先にある。両方の固定を解除する動画やサンプルサイズの固定も解除する動画も以下のリンク先の下の方にある。
twitter.com/genkuroki/stat...
タグ: 統計
posted at 10:24:38

「JR西日本社員が4名参加しており、しかも上位に入賞したんです。当初ノーマークだった社員が3位、8位に入り、ベンダーよりも社員のほうが順位が高いという結果になりました」 twitter.com/ledgeai/status...
タグ:
posted at 10:27:02
#統計 45度線より下のものの荷重平均は45度線より下になる。
しかし、45度線の上と下の両方にぶれているものの荷重平均は45度線に近付くことがあります。以下のリンク先はχ²検定で実際にそうなる様子を示す動画です。
twitter.com/genkuroki/stat...
タグ: 統計
posted at 10:28:14

須山敦志 Suyama Atsushi @sammy_suyama
>導入ありきで適切な課題設定をせずに、現場でAIがどう使われるのかまでを理解していなければ、AI活用は成功しないと言っていい twitter.com/Kenmatsu4/stat...
タグ:
posted at 10:31:56
#統計 縦横の合計をすべて固定した条件付き確率分布におけるピアソンのχ²統計量の分布とχ²分布の大きな違いをみて、χ²検定の誤差が大きいと判断することは、論理的には明瞭に間違い。
リンク先t=1が超幾何分布でのピアソンのχ²統計量の分布で、t=28が二項分布での分布。
twitter.com/genkuroki/stat...
タグ: 統計
posted at 10:34:45
非公開
タグ:
posted at xx:xx:xx

“赤字事業の撲滅”という言い方に、とても嫌な予感がする。 パナソニック、半導体撤退へ 台湾企業に売却:日本経済新聞 www.nikkei.com/article/DGXMZO...
タグ:
posted at 11:04:52
記録【AIの分析によって得られた「区別」であって、差別じゃない】www
AIという用語をこういう使い方をするようでは、一緒に仕事してくれる人がどんどん消えて行くと思う。
twitter.com/genkuroki/stat... pic.twitter.com/WHIiJkSXxE
タグ:
posted at 11:44:37

新谷貴司(HP制作リニューアル・SEO・ @localnavi
@genkuroki 【一緒に仕事してくれる人がどんどん消えて行くと思う。】
リアルタイムに今もこの人の会社の取引先とか寄付口座への出資先が消えて行ってませんか?
タグ:
posted at 11:46:43
ledge.ai/jr-west-data-s...
【当初ノーマークだった社員が3位、8位に入り、ベンダーよりも社員のほうが順位が高いという結果】
【上位入賞した2名はそれぞれ趣味でデータサイエンスに取り組んでおり、1人は自動改札機のメンテナンス部署に所属し、もう1人は新幹線の運転士だった】
いい話だ。
タグ:
posted at 11:51:10
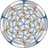
#Hyperbolic #tiling shown in the Poincaré disk model. Truncated {3,17}. pic.twitter.com/ANw6ltGvaw
タグ: Hyperbolic tiling
posted at 12:00:27

学歴ロンダって表現が出てくるにはそれなりの背景があるわけで。多くの大学で,社会人の受験を期待して小論文・研究計画プレゼン・面接等の結果で入学させるということが行われている。修士卒と同等の知識を実務経験で読み替えた場合,その分野の体系的な知識を欠いた人がすり抜けてくる。
タグ:
posted at 12:07:57
大学院重点化してしばらくの間は,どこの大学院も学力試験を課していたので,他大学に進学しても学歴ロンダとは言われなかった。その時代でも,東大先端研で社会人向け面接入試をやったら,他大の現役のM2が受けて合格したけど,低学力過ぎて修士を修了できず入学取り消しになったことがある。
タグ:
posted at 12:12:46
修士課程を修了できなくても東大の付属研究施設の博士課程の面接試験には通ることが証明されてしまったわけで,先生方も頭を抱えたらしい。プレゼン主体の試験をやると,プレゼンが上手な人が低学力を補って通ってしまうことがある。
タグ:
posted at 12:17:44
もちろん,他大修士→企業研究所→東大院,で来た人達はほとんどが優秀な人で,いろいろと教わることも多かった。ただ,とんでもないのがプレゼン試験をすり抜けてくることがあるのが困る。博士課程は研究テーマを絞ってしまうので,広範囲な知識を試されるとは限らない。
タグ:
posted at 12:20:52
分野としては生化学だったのだけど,他大修士→社会人向け入試を通過→学位取得(教授が主査,論文3報アクセプトが条件)→助手で別の大学に就職,で,就職した先で特定のpHになるように緩衝溶液を調整する計算ができなくて学生に馬鹿にされて職場に来なくなったというのがいたり。
タグ:
posted at 12:25:05
非公開
タグ:
posted at xx:xx:xx
社会人向けやりはじめたばかりの東大の一部がこの有様だったから,後から同様の入試をやった全国各地の大学で似たようなことが増えたんじゃなかろうか。特に大学院改組の後は,何年間何人以上に学位を出せと文科省の圧力がある。板橋ホタル博士は派手にやったから目立っただけで。
タグ:
posted at 12:31:32

だから,学歴ロンダという呼び方は努力や入ってからの成長を評価しないという主張もわかるのだけど,同時に,学歴ロンダと言いたくなる気持ちもわかる。研究成果とは別に,当該分野の標準的な学力をみる試験も課した方が,大学も大学院生も修了者を受け入れる社会も幸せになれそう。
タグ:
posted at 12:35:27
@Ra_koyama レシピはあって本も出てるから,作るだけなら何とかなる。ただ,そのレシピ本の存在さえ認識してなかった可能性が……。人が多かったから,誰かに聞けばなんとかなる状況ではあったけど,それで済ませると後からいろいろ困ることに。
タグ:
posted at 12:41:08
@kankimura 差別のある社会で分析を行えば、その分析結果も当然のことながら差別構造を反映したものになるので、中立性なんてないです。
AIの分析結果だから問題ないとか言っちゃう人は技術の素人として馬鹿にされますし、こういう扱いを受けます→ twitter.com/genkuroki/stat...
タグ:
posted at 13:23:41

#超算数
まんなからへん、激しくダウト センセガチャで外れを引いたらそうも言ってられない。 twitter.com/azuki112shuzo/...
タグ: 超算数
posted at 13:49:40

Stack Overflow Hot Q @SOHotQuestions
Multi-threaded parallelism performance problem with Fibonacci sequence in Julia (1.3)
stackoverflow.com/q/59078305/250...
#multithreading #coding #programming #developer #julia #fibonacci #julialang #juliaset #datascience #scientificprogramming #numericalcomputing pic.twitter.com/bVtaUZziH5
タグ: coding datascience developer fibonacci julia julialang juliaset multithreading numericalcomputing programming scientificprogramming
posted at 14:16:39

How the Grappler became the most effective way to stop a vehicle buff.ly/2MssGPv pic.twitter.com/gbQgfHJJ8B
タグ:
posted at 16:00:27


#Julia言語 ああ、なるほど
⭕️ for i = 1:n
❌ for i in 1:n
⭕️ for i in itr
❌ for i = itr
というスタイルを好む人たちがいるのか。
for i = 1:n は for i = 1,...,n とおいて同じノリなのだと思う。
私はすべて in を使うスタイル。
github.com/domluna/JuliaF...
タグ: Julia言語
posted at 18:23:46
大学として学生を守るのは当然だけど,削除するように指導するのは余計なことだしすべきでな。むしろそのままにして,やばいのがここにいるというのが分かるようにしておいた方が話が早い。下手に削除なんかされたら,これが消されました,って情報を拡散するこっちの手間が増えるので止めて欲しい。 twitter.com/Kyohhei99/stat...
タグ:
posted at 18:47:45

おそらく今のエコシステムの中で1番使い勝手の良いフォーマッタのJuliaFormatterは、デフォルトだとrhsが(astレベルで)UnitRangeの場合inを=に変更します。
(自ら「独善的」だと揶揄してますが笑)
issue追うとメインの開発者のStefanさんの意見が元になってるみたいですね。
github.com/domluna/JuliaF... twitter.com/genkuroki/stat...
タグ:
posted at 19:16:11

@tententonton2 @nananao2236 @genkuroki @nyanchin33 twitter.com/tententonton2/... このツイートをまとめに追加させて頂いてもよろしいでしょうか?
タグ:
posted at 19:42:16
@tententonton2 @nananao2236 @genkuroki @nyanchin33 このまとめに追加したいのですが
togetter.com/li/1429916
タグ:
posted at 19:42:59
#超算数 これ、よくありがちな「掛け算の順序」だと思ったけど、「8cmの3倍」というのは、地味にレアものじゃない?私は初めて見る気がするが、過去に報告されていたかな? twitter.com/tententonton2/...
タグ: 超算数
posted at 19:48:30

仲邑菫初段が馬場滋九段に勝った碁、KataGoをお供に観戦してました。このグラフは KataGo の示していた目数差です。白が大逆転に成功したあと損を重ねて200手目あたりからどちらに転ぶかわからない半目勝負が続いていたのがわかりますね。最後は負けを読み切った黒の玉砕でしょう。 pic.twitter.com/wuEeDy2e9n
タグ:
posted at 20:01:49


先日の文部科学委員会で、採点をした(する)ことは現時点では守秘義務には含まれていないという議論がありました。安心してご連絡ください。 twitter.com/y__hiroyuki/st...
タグ:
posted at 20:13:21
@musicisthebest_ 割合となるとさらにカオス。
200gの3割って200gが0.3個分だから200×0.3が正しい、とされているけど、
割合は1に対してどれだけと言う意味で、3割って1あたり0.3ということだから、金の含有率が3割なら、1gあたり金0.3gで、0.3×200こそが正しい
とも言えそう。
タグ:
posted at 20:13:24

中高の数学の先生も予備校や塾の数学の先生も、みんな掛け算の順序はどうでもいいって言ってるのに、それらの先生より数学的知識の乏しい小学校の先生が掛け算には順序があるって言っているのは、本当に厄介。
↓を見た息子「もう小学校では足し算引き算だけにしておいた方が子供のためじゃない?」 twitter.com/tententonton2/...
タグ:
posted at 20:19:21

@OokuboTact 面積云々じゃなくて、このような「倍」というのを文章問題に出してきて掛け算の順序に拘る採点があまり見た記憶がない、ということです。
大抵、「1人に3個ずつ」とかですよね?
タグ:
posted at 21:05:23

なんかこれに医学系の学生か院生らしいところから「素人は黙っとれ」的なクソリプが盛んに飛んでくるのですが、他の分野の研究不正の紹介では飛んでこないのを考え合わせるとなんか当該分野はほんま諸々大変なんやろなあと推察される。クソリプに少し答えるとコメント消えてしまうところにも闇を感じる twitter.com/smasuda/status...
タグ:
posted at 21:05:26

Sato Shuntaro|佐藤俊太朗 @Shuntarooo3
階層モデリング(混合効果モデル、mixed effect model)をアニメーションで理解できるサイト。
シンプルな線形モデルから混合効果モデルまで拡張させていく過程がよく分かります😁
mfviz.com/hierarchical-m...
タグ:
posted at 21:11:25
@musicisthebest_ 200gの塊があって、これを3:7に分割するということだと、200×0.3 金の含有のように、全体に均等に分布しているなら、0.3×200と使い分けたりして^^
タグ:
posted at 21:12:58

ごまふあざらし(GomahuAzaras @MathSorcerer
笑いすぎてお腹痛いできゅ!!!!! twitter.com/genkuroki/stat...
タグ:
posted at 21:23:05

形容詞の apparent と副詞の apparently は意味がちょっとズレてるから要注意.apparent は容易に見てとれる/理解できる「明らかに」;他方,apparently は伝聞(「~だそうだ」)または様子から推測して「~のようだ」みたいな意味で使われる,らしい.www.oxfordlearnersdictionaries.com/definition/eng...
タグ:
posted at 21:33:36
#統計 2×2の分割表の独立性のχ²検定の基礎付けの方針についての1枚のノートをついさっきささっと書きました(添付画像)。
大事なポイントは、最尤法の基礎の1つである「対数尤度比に関するWilksの定理」に帰着することです。
周辺度数全固定で超幾何分布に持ち込む議論は必要ない。 pic.twitter.com/a0a0o8XndC
タグ: 統計
posted at 22:22:56

統計力学初学者はスターリングの公式を使うのを胡散臭く感じると思うんだけど、あれはまさに示量的な物理量の示量的な部分を取り出す操作だから、統計力学では相当本質的だよね
タグ:
posted at 22:29:03
#統計 Wilksの定理はnuisance parametersを残したままで、G統計量やピアソンのχ²統計量が漸近的にχ²分布に従うことを保証してくれます。
nuisance parametersを固定するために周辺度数全固定に走ると、有限サンプルサイズでの誤差の大きさの評価を間違う危険性がある。
twitter.com/genkuroki/stat...
タグ: 統計
posted at 22:58:19
試行調査の結果報告を読んでいる。
ここにも数学の記述問題で途中過程を記述した受験生がいたと書いてある。その対策として解答欄を狭くするらしい。どうして問題文に指示を明記しない?
タグ:
posted at 23:04:56
#統計 というわけで、#Julia言語 で書いた2×2の分割表の検定のサンプルコードをまとめて
nbviewer.jupyter.org/gist/genkuroki...
で公開しておきました。基本函数は
twobytwo_test(a, b, c, d; α=0.05, ω=1.0)
αは有意水準でωはオッズ比の帰無仮説値。
添付画像では #R言語 の函数の出力と比較しています。 pic.twitter.com/I9qqMxoFM1
posted at 23:20:01
#統計 #Julia言語 変更した。
nbviewer.jupyter.org/gist/genkuroki...
Rejection probabilityも表示されていると、Fisher's exact testの強い有限離散性の悪影響も見積もれるので相当に安心な感じがします。検定力が弱まって価値ある知見を見逃すことにも配慮できた方がよい。 pic.twitter.com/k8SoGR4Niq
posted at 23:49:53
#統計
nbviewer.jupyter.org/gist/genkuroki...
にライセンス表示もつけておきました。
Copyright 2019 Gen Kuroki
License: MIT
opensource.org/licenses/MIT
ja.osdn.net/projects/opens...
MITライセンスだということは基本的に「自由に使って下さい」という意味です。改変・配布・販売も私に無断で行えます。
タグ: 統計
posted at 23:54:00
